【kubernetes由浅入深的总结】
前言
使用了kubernetes很多年,经历了从0.x到1.x等版本的迭代,不少知识点和使用方式已经发生了改变,特此记录。多年以后,就算用不着了kubernets集群,但是kubernets对一个运维的影响也不可磨灭,总之,记录一下。
一、基础概念
核心组件
- 解释 Kubernetes Master 节点的核心组件及其作用(API Server、Scheduler、Controller Manager、etcd)。
API Server
作为集群的前端和网关,所有组件和用户都通过它进行交互。
关键功能:
- 提供resful api:接收来自kubectl/dashboard/其他组件或外部客户端的请求,比如创建pod/service等。
- 认证和授权,验证用户、服务的权限
- 请求校验和准入控制:检查资源定义是否合法,比如pod 的resources.limits是否合理。
- 数据读写的中介:所有对集群状态的修改(比如创建、删除pod)都通过API SERVER持久化到ETCD。
特点:
- 无状态,可水平扩展,多个实例共享负载
- 是唯一直接与etcd通信的组件,其他组件必须通过API SERVER 访问数据。
Scheduler
决定pod应该运行在哪个node上。
关键功能:
- 监听未调度的pod:通过API SERVER监听spec.nodeName为空的pod
- 过滤和打分:
- 过滤阶段,排除不符合条件的node,比如资源不足、不满足节点亲和性
- 打分阶段,对剩余node评分(比如选择资源利用率最低的节点)
- 绑定pod到node,将调度决策(spec.nodeName)通过api server 写入到ETCD
示例:如果一个pod请求4G内存,scheduler会跳过只有2G内存的node;支持自定义调度策略(优先调度到GPU节点)
Controller Manager
运行各种控制器,确保集群的实际状态和期望状态一致。
核心控制器:
- deployment:监控deployment对象,确保指定数量的replicaSet副本在运行。
- ReplicaSet: 确保pod副本数符合预期
- node:监控node状态,处理不可用节点(如标记为notReady)
- service:管理service和endpoints的关联关系
工作原理:
- 通过API SERVER监听资源变更(如用户创建了一个deployment)
- 对比当前状态和期望状态(如实际pod数和replicas配置)
- 调用API SERVER执行调整(如创建新的pod)
ETCD
kubernetes的分布式键值存储数据库,保存集群的所有关键数据
存储内容:
- 集群配置(如configMap、Secret)
- 资源对象状态(如pod、service、deployment的定义和当前状态)
- 集群元数据(如node信息、角色标签)
关键特性:
- 强一致性:所有读写操作需要多数节点确认,保证数据一致性
- 高可用:通常以奇数节点部署,容忍部分节点故障
- 唯一数据源:只有API SERVER能直接读写ETCD,其他组件通过API SERVER间接访问。
注意:
- 备份ETCD数据是恢复集群的关键(使用 etcdctl snapshot save)
- 性能敏感:大规模集群需要优化ETCD,如SSD存储、独立部署
kubelet
核心职责:
- pod的生命周期管理:
- 监听APISERVER 分配的pod清单
- 调用Docker启动/停止容器
- 确保Pod中所有容器正常运行(如崩溃后自动重启)
- 资源监控,向master报告节点和Pod的状态
- Volume和网络挂载:
- 按照Pod定义挂载存储卷(如hostPath、NFS)
- 配合CNI插件配置Pod网络命名空间
- 关键特性:
- 直接操作容器
- 不管理非kubernetes创建的容器
kube-proxy
核心职责:
- service网络代理:
- 维护节点上的网络规则(通过iptables/ipvs模式),实现:
- service的clusterIP访问(将请求转发到后端pod)
- NodePort/LoadBalancer 流量路由
- 会话亲和性
- endpoint同步:监听apiserver 的endpoint变化,实时更新转发规则(如Pod扩缩容后更新IP列表)
- 维护节点上的网络规则(通过iptables/ipvs模式),实现:
工作模式:
模式 原理 适用场景 iptables 通过 Linux 内核的 iptables规则链实现流量转发(默认模式)。中小规模集群 IPVS 使用内核的 IPVS(L4 负载均衡),规则规模大时性能更高。 大规模集群(Service 多) userspace 代理流量通过用户空间程序(已弃用,性能差)。 不推荐使用 示例:
- 当访问
Service的ClusterIP:80时,kube-proxy的iptables规则会将请求随机转发到一个后端 Pod(如10.244.1.2:8080)。
组件协作示例
- 用户:执行
kubectl create -f pod.yml - API SERVER:校验请求合法性-》写入ETCD(此时pod状态为pending)
- scheduler:发现未调度的pod-》选择合适的node-》通过API SERVER更新pod的nodeName
- Controller Manager:确保node上的kubelet已经启动pod,如未运行,触发重新调度
- kubelet: 监听到分配给自己的pod-》调用容器运行时启动容器
- API SERVER: kubelet上报pod状态如running-》写入ETCD。
总结
组件 核心职责 高可用部署建议 API Server 集群入口,认证授权,数据读写中介 多实例 + 负载均衡 Scheduler 决策 Pod 调度到哪个 Node 多实例(仅一个生效) Controller Manager 确保资源状态符合预期(如副本数) 多实例(Leader 选举) etcd 持久化存储集群数据 3/5 节点分布式部署 故障影响:
- API Server 宕机:集群无法管理(但已运行的 Pod 不受影响)。
- etcd 宕机:集群完全不可用(无法读取或更新状态)。
- Scheduler/Controller Manager 宕机:无法创建新资源,但已有资源继续运行。
通过理解这些组件的职责,可以更好地诊断集群问题(如 Pod 卡在
Pending状态可能是 Scheduler 故障)。- Worker 节点上必须运行哪些组件?
kubelet和kube-proxy的作用是什么?- 必须运行的组件:
- kubelet,负责和master通信,管理pod和容器的声明周期(启动、停止、监控)
- Kube-proxy, 维护节点上的网络规则(如service的负载均衡、iptables规则)
- 实际运行容器的引擎,比如Docker
- 可选组件:
- cAdvisor,通常内置于kubelet,收集节点和容器的监控数据
- 日志收集器,将容器日志发送到集中式存储
- CNI插件,如Calico/Flannel,实现pod网络通信。
- 必须运行的组件:
- worker节点组件协作流程
- Pod启动。
- kubelet收到APIServer 下发的pod定义,调用容器引擎启动容器
- kube-proxy 检测到新Pod的IP,更新iptables规则(如果该Pod属于某个service)
- service 访问:用户访问clusterIP-》kube-proxy 的规则将流量转发到Pod
- 监控和自愈,kubelet发现容器崩溃-》自动重启容器并上报状态给API SERVER
- Pod启动。
资源对象
Deployment、StatefulSet、DaemonSet 的区别及适用场景?
- Deployment
- 管理无状态应用(Pod可以随意替换),支持滚动更新和回滚,通过ReplicaSet控制副本数
- 使用web服务、API、无状态微服务(NGINX、前端)
- StatefulSet
- 管理有状态应用(pod有唯一标识和持久存储),固定网络标识(如Pod名称+序号),按顺序部署/扩展
- 适用数据库(MySQL、MongoDB)、消息队列、有状态服务(ETCD、Zookeeper)
- DaemonSet
- 每个Node上运行一个Pod副本,适合集群级守护进程,忽略调度策略
- 适合日志收集、监控、网络插件、存储插件
- Deployment
Service 的 ClusterIP、NodePort、LoadBalancer 类型有何不同?
类型 访问方式 适用场景 示例 YAML 片段 ClusterIP - 集群内部 IP(默认类型) - 仅集群内 Pod 可访问 内部服务通信(如微服务间调用) type: ClusterIPNodePort - 在集群所有节点的固定端口(30000-32767)暴露服务 - 可通过 NodeIP:Port从外部访问开发测试、临时外部访问 type: NodePortnodePort: 31000LoadBalancer - 自动创建云提供商的负载均衡器(如 AWS ALB、GCP LB) - 外部流量直接接入 生产环境对外暴露服务(如公网访问) type: LoadBalancer
网络模型
- Pod 之间如何通信?跨节点通信如何实现?
- 解释 CNI(Container Network Interface)的作用,列举常见的 CNI 插件(如 Calico、Cilium)
Pod间网络通信
Kubernetes 的网络模型要求:
- 每个Pod都拥有唯一的IP地址
- 所有Pod可以直接通过IP通信,无需NAT(无论是否跨节点)
实现方式:
- CNI插件:通过CNI插件(如calico、flannel)配置底层网络,确保Pod间连同
- Overlay网络:部分插件(如flannel的VXLAN模式)通过封装数据包实现跨节点通信
- 路由模式:部分插件(如calico的BGP模式)通过节点路由表直接转发数据包
通信示例:
- 同一节点:通过Docker创建的虚拟网桥(cni0)直接通信
- 跨节点:数据包通过节点网络接口(如eth0)转发到目标节点
节点间网络通信:
- 节点间需要L3连通,可通过物理网络、云网络或者Overlay网络实现
- CNI插件负责解决跨节点路由问题
典型跨节点通信流程:
1. 源Pod发送数据包到目标Pod IP
1. 源节点的CNI插件识别目标IP属于另一节点,封装数据包为VXLAN格式
1. 封装后的数据包通过节点的eth0发送到目标节点
1. 目标节点解封数据包并转发到目标Pod
二、日常运维操作
- 命令与调试
- 如何查看某个 Pod 的详细错误日志?如果 Pod 处于
CrashLoopBackOff状态,如何排查? - 如何在不重启 Pod 的情况下更新 ConfigMap 的配置?
- 如何查看某个 Pod 的详细错误日志?如果 Pod 处于
- 扩缩容与滚动更新
- 如何手动扩展 Deployment 的副本数?滚动更新的策略如何配置?
- 金丝雀发布(Canary Release)在 Kubernetes 中如何实现?
- 存储管理
- PVC(PersistentVolumeClaim)和 PV(PersistentVolume)的工作流程是什么?
- 如何调试 Pod 挂载 Volume 失败的问题?
三、故障排查
节点故障
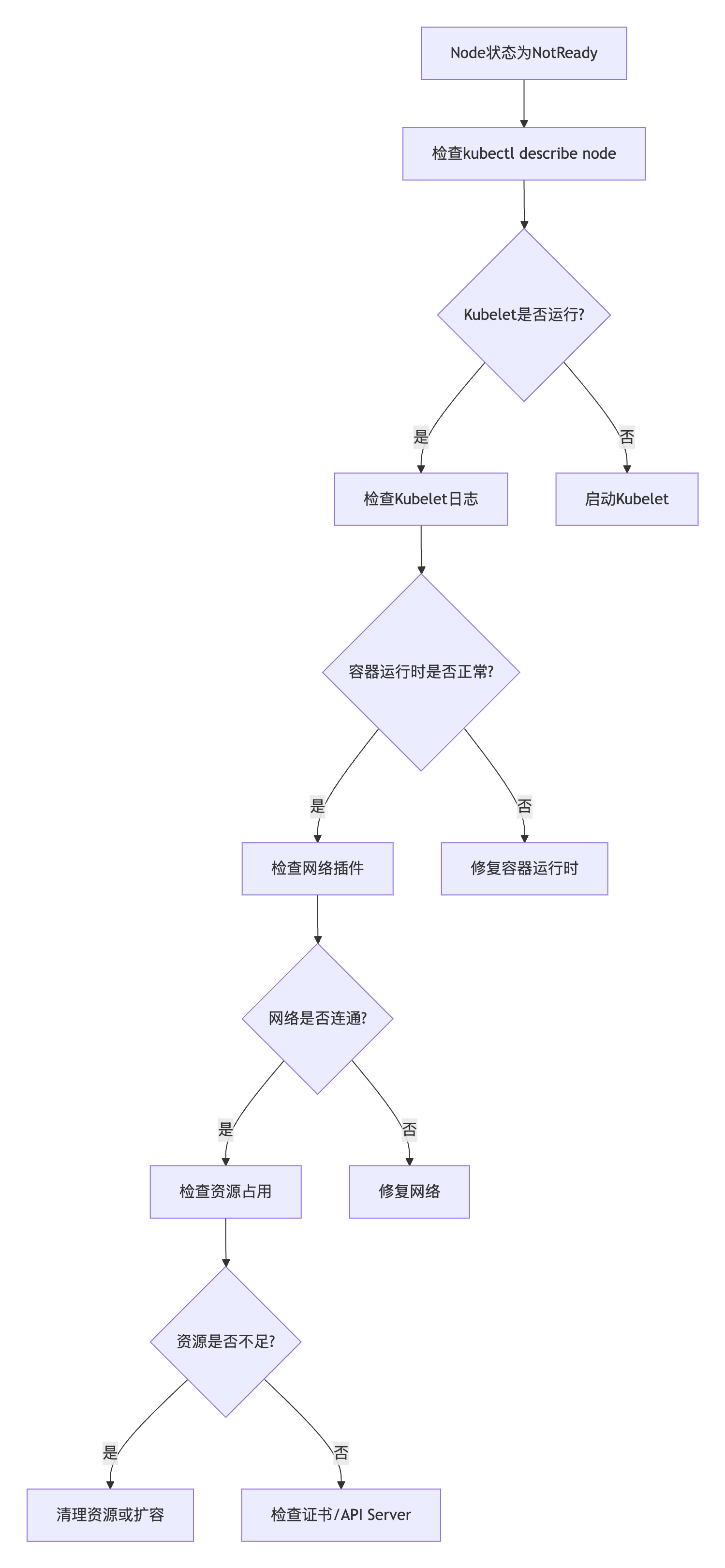
某个 Node 状态为
NotReady,如何逐步排查原因?![sNJz8Q]()
如何安全驱逐一个节点上的所有 Pod?(
kubectl drain的注意事项)- 驱逐前检查节点上的Pod
- 处理Daemonsets管理的Pod
- 处理持久化存储的Pod
- 处理长任务Pod(等待job跑完)
- 设置优雅终止时间
- 设置超时时间
- kubectl drain
–ignore-daemonsets \ # 忽略 DaemonSet 管理的 Pod
–delete-emptydir-data \ # 删除 EmptyDir 数据
–force \ # 强制驱逐无控制器管理的 Pod(如裸 Pod)
–timeout=5m # 超时时间
- 首先将Node标记为不可调度
- 执行驱逐
- 验证驱逐结果,检查pod是否已经重建
网络问题
- 用户反馈 Service 无法访问,如何从 Pod、Service、Ingress 逐层排查?
- 检查Pod的状态和配置
- 测试Pod是否可以访问,可以从集群内部测试或者进入Pod测试
- 检查Pod的日志和事件,比如镜像拉取失败和应用启动崩溃
- 检查service层
- 确认配置:clusterIP/Port;标签是否匹配;endpoints,检查service是否关联到了正确的Pod
- 测试service配置: 判断service类型是否正确,确认是clusterIP、nodePort还是LoadBalancer;检查端口映射是否错误
- 检查kube-proxy和网络插件
- 检查ingress层,检查ingress的path和backend、证书
- 检查Pod的状态和配置
- 如何检查集群 DNS(CoreDNS)是否正常工作?
- 用户反馈 Service 无法访问,如何从 Pod、Service、Ingress 逐层排查?
性能问题
- 如何发现集群中的资源瓶颈(CPU/内存)?如何优化 Pod 的
requests/limits配置? - 如何分析
kube-apiserver的高延迟问题?- 资源瓶颈分析:
- CPU、内存资源不足,垂直扩容或者水平扩容
- ETCD存储性能瓶颈,写入延迟高,日志中出现apply request took too long
- 请求流量分析
- 网络问题:
- 节点间网络延迟,测试API SERVER和ETCD节点间的延迟
- 检查网络丢包
- 负载均衡问题,检查后端节点的健康状态和连接数
- 资源瓶颈分析:
- 如何发现集群中的资源瓶颈(CPU/内存)?如何优化 Pod 的
四、安全与优化
- 安全实践
- 如何限制某个 Namespace 的 Pod 只能访问特定资源(NetworkPolicy)?
- ServiceAccount 的权限如何通过 RBAC 控制?举例说明 Role 和 ClusterRole 的区别。
- 集群优化
- 如何减少
kubelet的 CPU/内存占用? - 如何优化大规模集群的调度性能?(提示:优先级调度、动态资源分配)
- 如何减少
- 备份与高可用
- 如何备份和恢复 etcd 数据?
- 如何设计一个高可用的 Kubernetes 集群(Master 节点多实例部署方案)?
高可用集群
1. Master节点多实例部署(至少3个节点)
奇数节点避免脑裂的问题,可以通过Raft协议(ETCD)实现一致性。
部署方式:
- stacked模式,每个master节点部署API SERVER、kube-scheduler、kube-controller-manager、ETCD。
- 节省资源,适合小规模部署
- ETCD和master组件耦合,故障可能相互影响
- Extermal etcd模式,ETCD集群独立于api-server部署
- 解耦ETCD和master,适合生成环境
- 需要额外资源
Master 组件配置
- kube-apiserver:启用
--endpoint-reconciler-type=lease支持动态端点。 - kube-controller-manager 和 kube-scheduler:
- 通过
--leader-elect=true启用领导者选举。 - 设置
--bind-address=0.0.0.0允许跨节点通信。
- 通过
2. 负载均衡层
将流量均匀分发到多个API SERVER实例。
- 实现方式:
- 硬件负载均衡器(如 F5、AWS ALB)。
- 软件负载均衡器(如 HAProxy + Keepalived、Nginx)。
- 关键配置:
- 健康检查:监听 apiserver 的
6443端口和/healthz端点。 - 会话保持:禁用(Kubernetes API 无状态服务)。
- 客户端的每个请求都应该被视作独立请求,无需绑定到特定master节点。
- 防止负载均衡不均
- 避免与kubernetes自身的重试机制冲突
- 健康检查:监听 apiserver 的
五、场景设计题
- 设计题
- 假设集群中有 1000 个节点,突然出现大量 Pod 被驱逐(Evicted),如何快速定位原因并恢复?
- 如何设计一个自动化方案,监控所有 Deployment 的镜像版本并自动告警过期的版本?
- 版本与生态
- 你熟悉哪些 Kubernetes 发行版(如 OpenShift、RKE)?它们的优缺点是什么?
- 如何从 Kubernetes 1.24 升级到 1.30?列举关键步骤和风险点。
六、工具与扩展
- 周边工具
- 你用过哪些 Kubernetes 运维工具(如 Helm、ArgoCD、Velero)?简述它们的用途。
- 如何通过 Prometheus 监控 Kubernetes 集群的自定义指标?
- 扩展开发
- 如何编写一个简单的 Operator?CRD(Custom Resource Definition)的作用是什么?
考察重点
- 基础扎实:能清晰解释核心概念(如 Pod 生命周期、Service 负载均衡)。
- 实战经验:对故障排查有方法论(如从日志、事件、监控入手)。
- 安全意识:熟悉 RBAC、NetworkPolicy、Secret 加密等最佳实践。
- 自动化思维:能结合 CI/CD 或 Operator 提升运维效率。
附加建议
- 对候选人可追问 “你在实际工作中遇到的最难解决的 K8s 问题是什么?” 以考察真实经验。
- 要求候选人手写命令或 YAML 片段(如创建一个 Deployment 并暴露 Service)。