【爬虫实战】使用Python和JS逆向拉勾网的XS值
前言
之前的两篇都是分析了webpack技术的网站,今天分析一个特殊webpack的网站——拉勾网。该网站的特点是加载器和功能函数都是在一块的。
一、目标分析
这种招聘网站主要功能就是搜索职位、公司和投简历,所以主要目标如下:
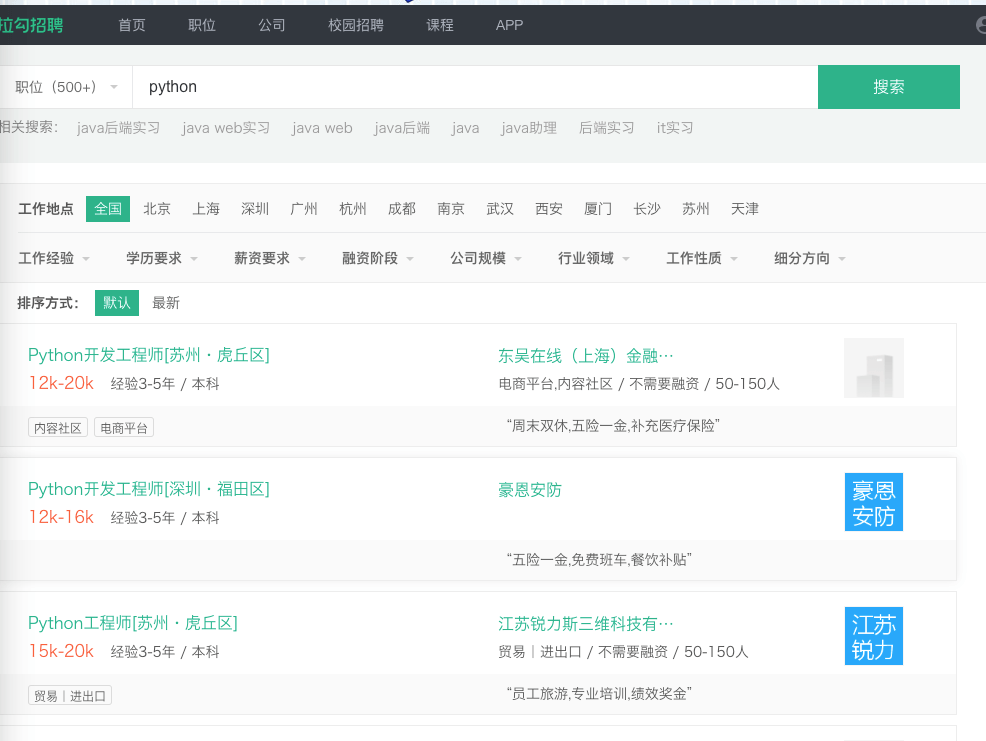
通过关键字搜索到岗位信息。
二、逻辑分析
1. 分析请求
可以看到特殊的接口:
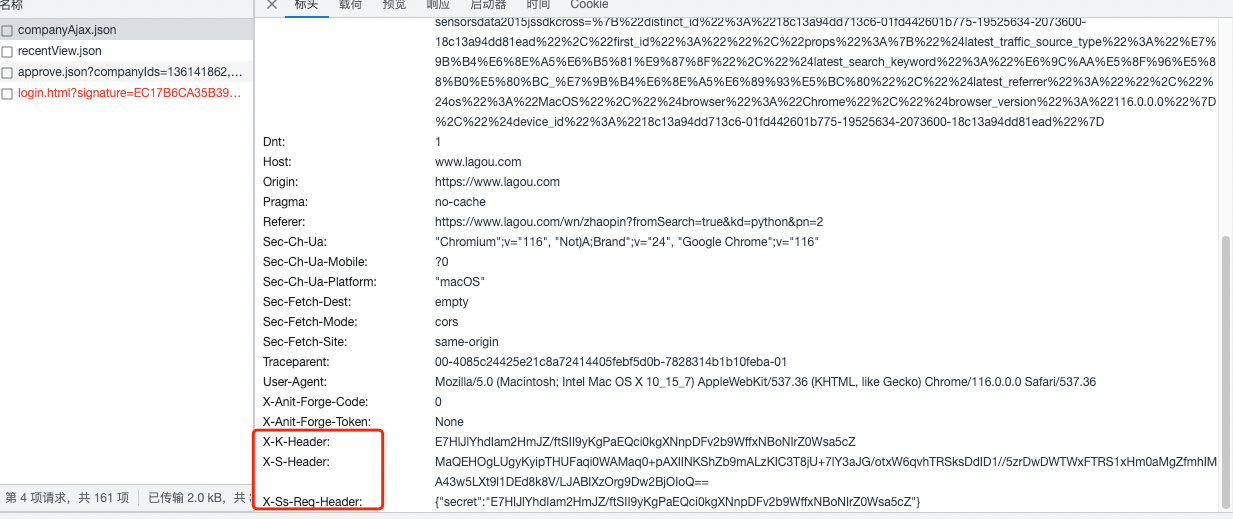
只有三个XS值的字段比较特殊,载荷也是加密的:

响应数据也是密文,所以之后需要解密:

2. 定位加密函数
定位函数一般常用的两种方式,搜索关键字或接口。搜索关键字:
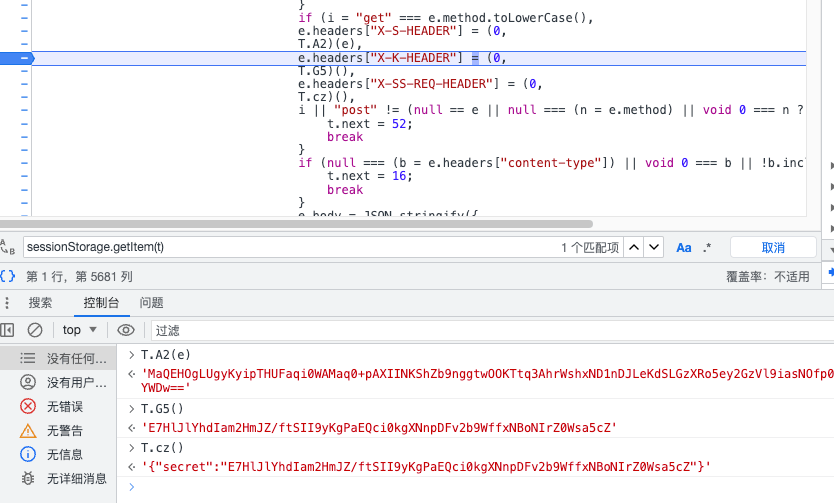
很巧,只有一条记录,并且三个都在一块呢。需要注意这种带逗号的写法,取右边的值。
可以看出这里的T就是重点,但是这个T对象是哪来的呢,肯定离的不远,往前看看有没有?果然就在前面不远的地方,这就是一个webpack的典型写法,下一步就要去找调度器。那么这里的加载器要去找r,断点后需要刷新才可以。

在这里,点进去就看到调度器:
1 | function i(t) { |
但是这里的i函数不是一个单独的自执行函数,调用功能的代码和调度器都写在一个文件了。所以,扣代码的时候,就直接把整个文件全部拷走。
3. 补JS
提示ReferenceError: window is not defined
1 | window = global; |
ReferenceError: XMLHttpRequest is not defined
1 | XMLHttpRequest = {}; |
接下来
1 | // 最主要的就是i函数 |
提示ReferenceError: sessionStorage is not defined,在控制台输入sessionStorage,将获取的对象放入代码中。
提示TypeError: sessionStorage.getItem is not a function,增加个方法:
1 | sessionStorage.getItem = function (key) { |
最后输出:

接下来补X-K-HEADER。
1 | e = { |
输出:
1 | X-S-HEADER MaQEHOgLUgyKyipTHUFaqi0WAMaq0+pAXIINKShZb9mALzKIC3T8jU+7lY3aJG/otxW6qvhTRSksDdID1//5zrDwDWTWxFTRS1xHm0aMgZfmhIMA43w5LXt9l1DEd8k8V/LJABIXzOrg9Dw2BjOIoQ== |
4. 定位请求体加密函数
虽然能直接通过搜索接口地址的方式找到一条记录,但是这里不是我们想要的,我们需要的是密文,而不是加密前的数据。
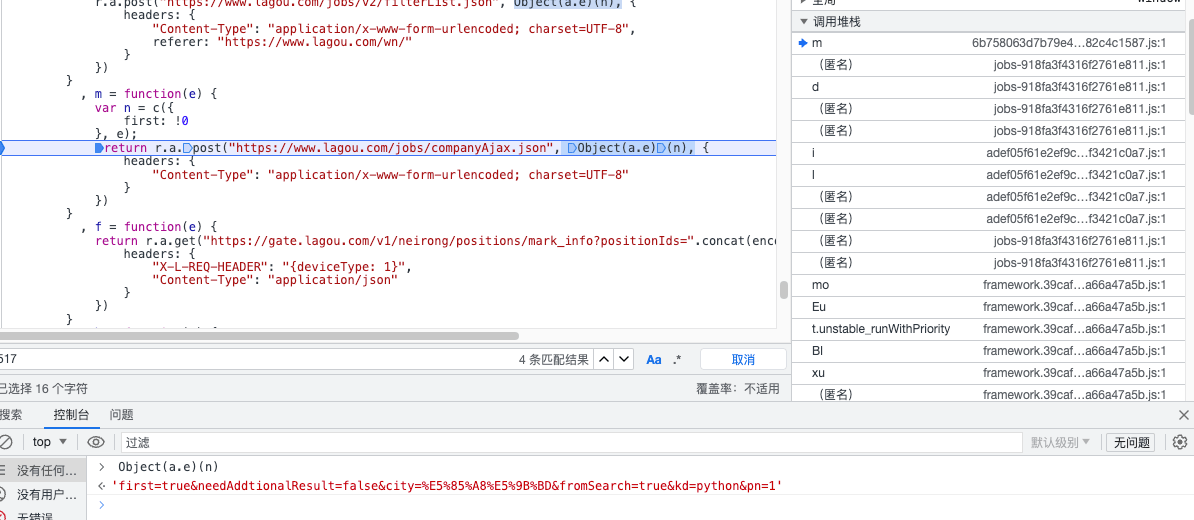
所以还是需要用启动器的方式来追踪。
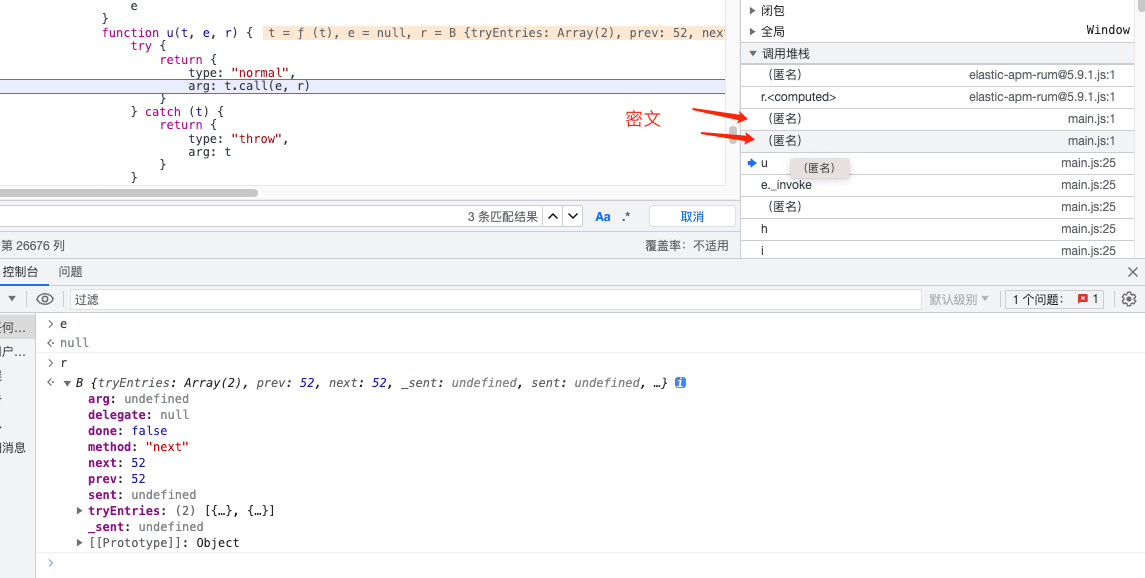
可以看到之前都是密文,但是之后就没有了,所以关键就出现在倒序最开始密文的地方。
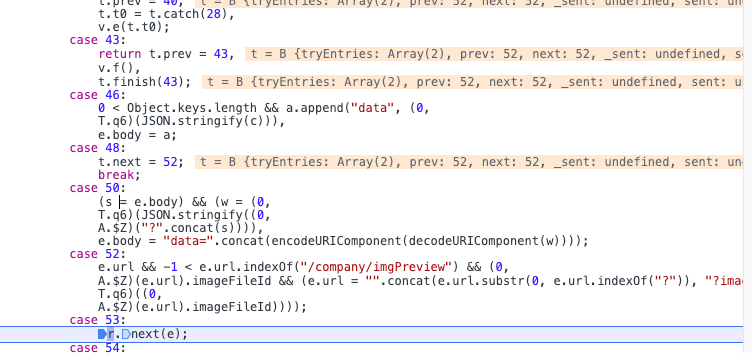
可以这这个断点周围看看,有没有类似data或者code、body的代码,然后打上断点试试。
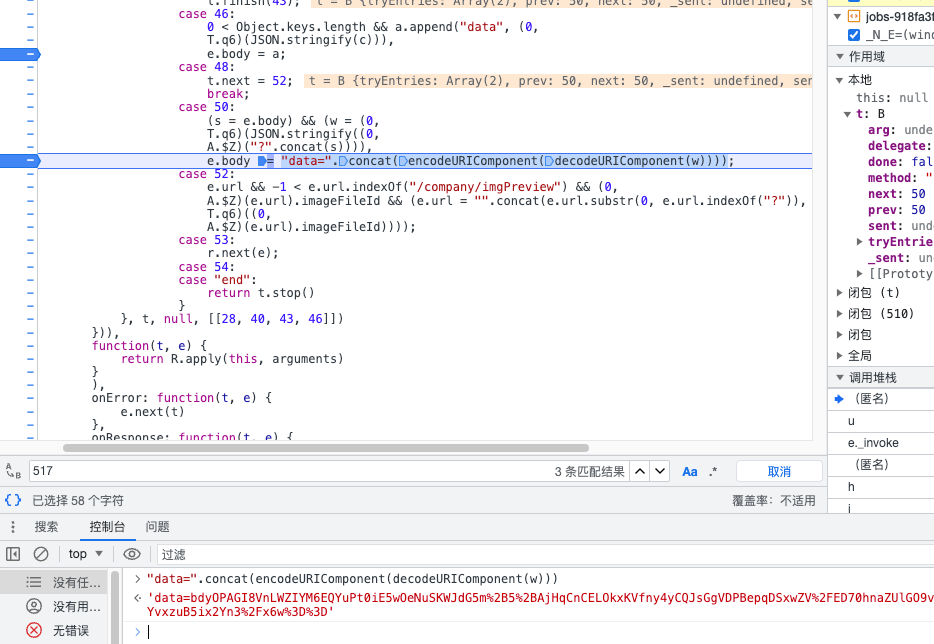
可以看到case 50这里出现了,关键变量就是w,重点就是前面的代码:
1 | (s = e.body) && (w = (0, |
处理成正常格式:
1 | w=T.q6(JSON.stringify(A.$Z("?".concat(s)))) |
5、请求体JS代码
1 | A = window.xs(375) |
三、代码实现
Python部分:
1 | import json |
但是IP受限了,之后再看。