近期重新拾起来了久违的爬虫,有时候就想练练手,正好想起来了某个博客平台,虽然这个平台的评价不高,但是也是有一定存在意义的。那就用Python的方式的方式刷一下阅读量吧。
目标分析
获取目标数据
首先要获取所有文章的列表,一般只有两个方式:
- 从个人主页获取
- 从创作中心也就是个人后台获取。
很明显从个人主页的位置获取更简单,因为不需要登录,完全没有任何必要给自己找麻烦。
![]()
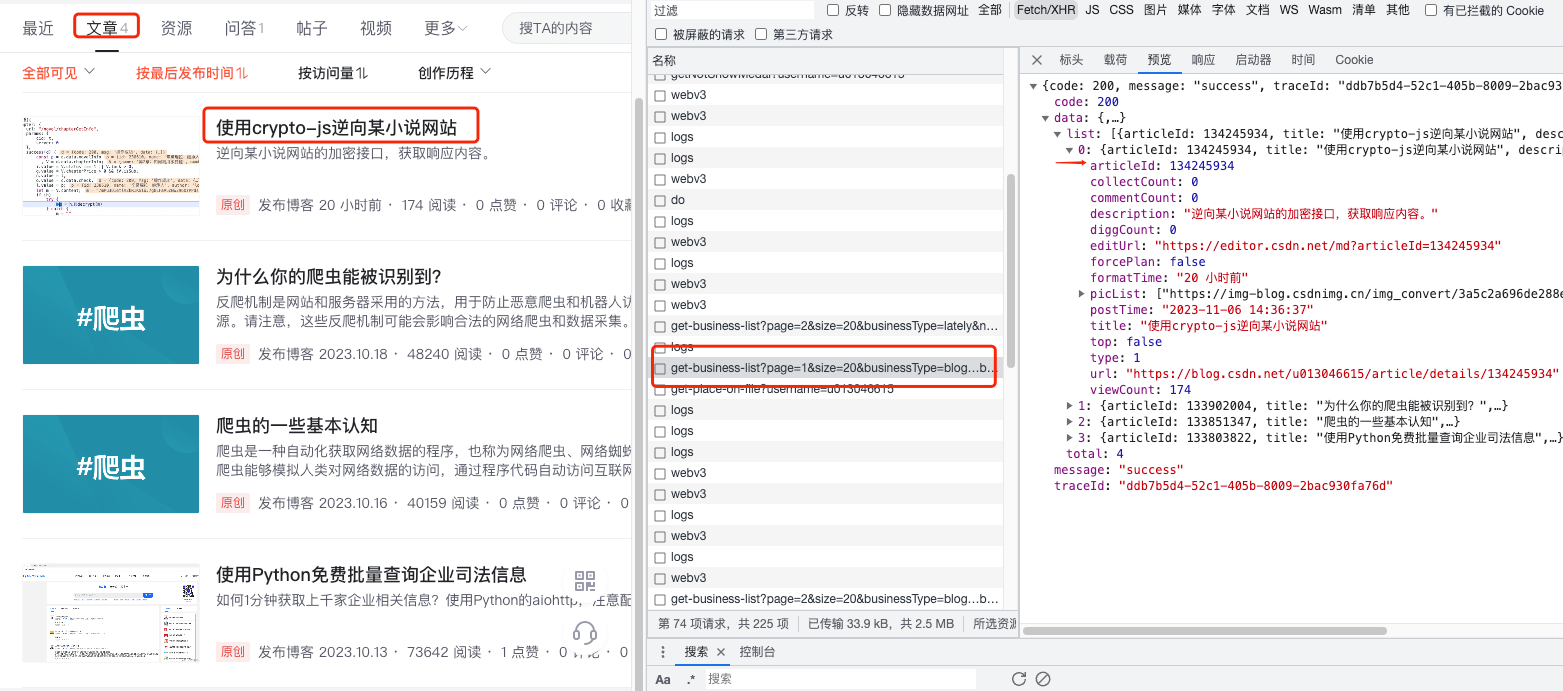
我们要的是文章的版块所以选择文章,在开发者工具中看到有个接口get-business-list提供了我们需要的数据:
其实到这里,我们能拿到文章ID或者URL就可以了。
分析接口
接下来我们具体分析这个接口情况
![]()
载荷部分很简单,定义了页数索引和size以及username等数据。
然后再看一眼请求头,如果没有特殊字段就好办了。
![]()
很明显,只有一个cookie,但是这个cookie是必须的吗,也不一定,待会试试就可以了。直接复制完整URLhttps://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=u013046615 发起get请求。
![]()
的确可以直接请求,可以没有cookie。
那么到这里,我们就清晰了获取文章ID的整个过程,接下来就可以考虑代码的思路了。
代码思路
代码的整体思路如下:
- 首先获取文章ID或URL(URL其实也可以自己去拼接)
- 根据文章信息进行requests请求
获取文章信息的代码
1
2
3
4
5
6
7
8
| def get_id_from_api():
api_url = 'https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog' \
'&orderby=&noMore=false&year=&month=&username=u013046615'
resp = requests.get(api_url, headers=headers)
all_ids = list()
for i in resp.json()['data']['list']:
all_ids.append(i['articleId'])
return all_ids
|
![]()
将数据进行提取,主要是最后的文章ID,也可以直接使用URL,这都无所谓。
进行文章访问的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| async def pv(id):
async with semaphore:
try:
async with aiohttp.ClientSession(timeout=timeout) as session:
async with session.get(f'{url}{id}', headers=headers,proxy=proxy) as resp:
await asyncio.sleep(random.uniform(1.0, 3.0))
if resp.status == 200:
return True
else:
return False
except Exception as e:
return False
|
这里使用的是aiohttp,使用requests也可以。将文章ID传入,然后进行访问,至于返回结果无所属,只要阅读数上升了,就算有一些异常也无关紧要。这里建议使用一些代理,否则可能接口返回异常的可能性大一些。
最后还是要sleep以下,否则容易被ban掉,也算是对自己负责吧。
整体代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
|
"""
@time:2023/10/13
@file:csdn.py
@author:medivh
@mail:admin@econow.cn
@IDE:PyCharm
"""
import asyncio
import random
import ssl
import time
import aiohttp
import requests
from tqdm import tqdm
from multiprocessing import freeze_support
freeze_support()
user_agent_list = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; …) Gecko/20100101 Firefox/61.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15",
]
headers = {"User-Agent": random.choice(user_agent_list)}
host = "https://blog.csdn.net"
url = "https://blog.csdn.net/u013046615/article/details/"
def get_id_from_api():
api_url = 'https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog' \
'&orderby=&noMore=false&year=&month=&username=u013046615'
resp = requests.get(api_url, headers=headers)
all_ids = list()
for i in resp.json()['data']['list']:
all_ids.append(i['articleId'])
return all_ids
async def pv(id):
async with semaphore:
try:
async with aiohttp.ClientSession(timeout=timeout) as session:
async with session.get(f'{url}{id}', headers=headers,proxy=proxy) as resp:
await asyncio.sleep(random.uniform(1.0, 3.0))
if resp.status == 200:
return True
else:
return False
except Exception as e:
return False
async def main():
i = 0
total_lines = 9999999
pbar = tqdm(total=total_lines, desc="进度")
id_list = get_id_from_api()
weights = [1 / (i + 1) for i in range(len(id_list))]
while i < total_lines:
num_list = [num for num in range(1, 14)]
selected_id = random.choices(id_list, weights=weights, k=1)[0]
tasks = [asyncio.create_task(pv(selected_id)) for _ in num_list]
await asyncio.wait(tasks)
pbar.update(1)
i += 1
if __name__ == "__main__":
start_ts = time.time()
sslgen = SSLFactory()
semaphore = asyncio.Semaphore(10)
timeout = aiohttp.ClientTimeout(total=10)
asyncio.run(main())
print(f'耗时:{time.time() - start_ts}')
|
测试结果
![]()
可以对比前面的截图中的viewCount 174多了好几百,在个人中心也可以看到同样的数据,真实有效!
总结
实现刷阅读量的功能很简单,思路也很简单,没有什么逆向的过程。当然代码也有一些优化的潜力,比如:
- 目前是获取了第一页的文章列表,可以根据第一次请求的总数算出需要请求多少页
- 也可以加上定时任务,比如只有工作日的时候刷,毕竟很少有人大半夜闲的没事干读技术文章
![]()