request_time和upstream_response_time的区别
定义
一个正常的请求过程如下:
- 用户发出请求
- 建立NGINX连接
- 发送响应
- 接收程序的响应数据
- 关闭NGINX连接
request_time
request processing time in seconds with a milliseconds resolution; time elapsed between the first bytes were read from the client and the log write after the last bytes were sent to the client.
指的就是从接受用户请求的第一个字节到发送完响应数据的时间,即包括接收请求数据时间、程序响应时间、输出响应数据时间。
对于此部分对应的是1+2+3+4+5。
upstream_response_time
keeps times of responses obtained from upstream servers; times are kept in seconds with a milliseconds resolution. Several response times are separated by commas and colons like addresses in the $upstream_addr variable.
是指从Nginx向后端(php-cgi)建立连接开始到接受完数据然后关闭连接为止的时间。
对于此部分对应的是2+3+4+5。
从上面的描述可以看出,$request_time肯定大于等于$upstream_response_time,特别是使用POST方式传递参数时,因为Nginx会把request body缓存住,接受完毕后才会把数据一起发给后端。所以如果用户网络较差,或者传递数据较大时,$request_time会比$upstream_response_time大很多。
如果要从access_log中查看较慢的接口的话,可以在log_format中加入$upstream_response_time。
分析
从网上看到下列一组图片,感觉画的很形象。
request_time是从接收到客户端的第一个字节开始,到把所有的响应数据都发送完为止。![1637907742862.png]()
upstream_response_time是从与后端建立TCP连接开始到接收完响应数据并关闭连接为止。![1637907762851.png]()


所以,request_time会大于等于upstream_response_time。
性能优化
对于较高的request—_time很可能是由于连接速度较慢的客户端造成的,对此无能为力,但是较高的request_time并不代表服务器或者程序的性能不够。总体来说,没必要在request_time上花费较多时间,而是应该重点关注upstream_response_time。
nginx log_format
1 | $remote_addr,$http_x_forwarded_for #记录客户端IP地址 |
NGINX的文件传输
sendile
参数sendfile on 用于开启文件高效传输模式,同时配合tcp_nopush on 和tcp_nodelay on 两个指令,可防止网络及磁盘I/O阻塞,提升Nginx工作效率。但需要注意的是,linux内核版本2.5.9以后的版本中两者是可以兼容的。
三个指令都开启的好处是,sendfile可以开启高效的文件传输模式,tcp_nopush开启可以确保在发送到客户端之前数据包已经充分“填满”, 这大大减少了网络开销,并加快了文件发送的速度。 然后,当它到达最后一个可能因为没有“填满”而暂停的数据包时,Nginx会忽略tcp_nopush参数, 然后,tcp_nodelay强制套接字发送数据。
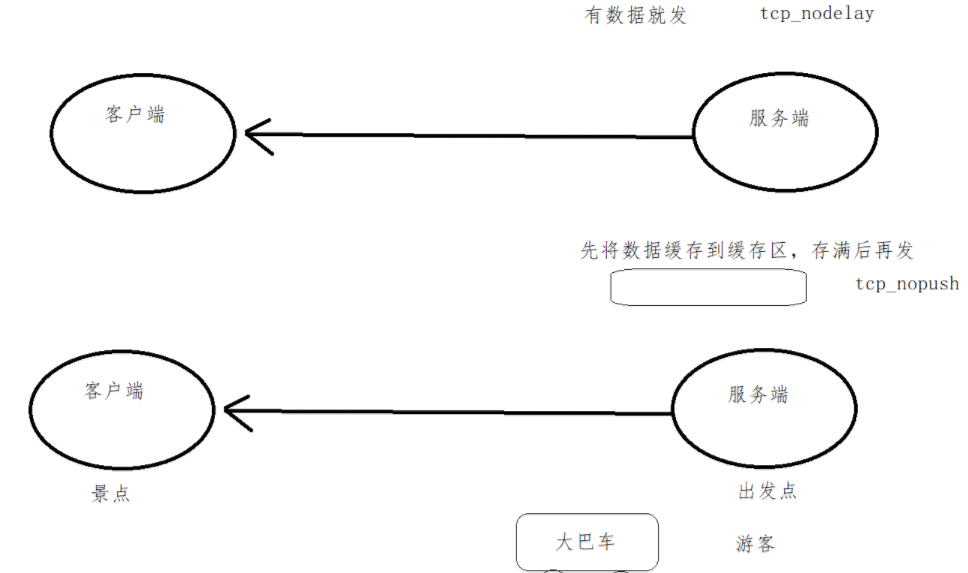
tcp_nopush
当有数据时,先别着急发送, 确保数据包已经装满数据, 避免了网络拥塞。需要我们等到数据量达到最大时才通过网络一次发送全部数据,这种数据传输方式有益于大量数据的通信性能,典型的应用就是文件服务器。
对于nginx配置文件中的tcp_nopush,默认就是tcp_nopush,不需要特别指定,这个选项对于www,ftp等大文件很有帮助。
tcp_nodelay
有时要抓紧发货, 确保数据尽快发送, 提高可数据传输效率。
总结
平时对request_time和upstream_response_time这两个参数没什么研究,关注的不多,主要关注request_time。但是最近阿里云的日志服务统计数据出现了异常,request_time和upstream_response_time的值完全违反了字段定义的原则。理论上request_time无论如何也会大于upstream_response_time的,但是客服死活不承认。无奈之下,好好研究一番,通过阿里云官网文档截图和历史正常数据已经现在的异常数据,客服最终承认存在问题,表示整改。
事实证明,阿里云的客服技术水平也是良莠不齐。
经过此次事件,也遇到了一些Markdown语法的问题,不过幸运的是vs code提供了很多帮助,能直接定位到问题,而对应的问题都有参考方案。