kubernetes 常见问题的探讨
关于kubernetes 部署复杂是其特点之一,而网络问题则是最为常见的类型之一。
场景 a/b/c node上的pod互通,但是对d node无法访问
- 个别服务出现无法访问另一个服务的情况;
- 测试判断无法ping通;
- 080端口无法访问;
- 经测试其他node上的pod均无法访问该node上的pod。
根据以上背景,初步断定是网络问题。
通讯链路
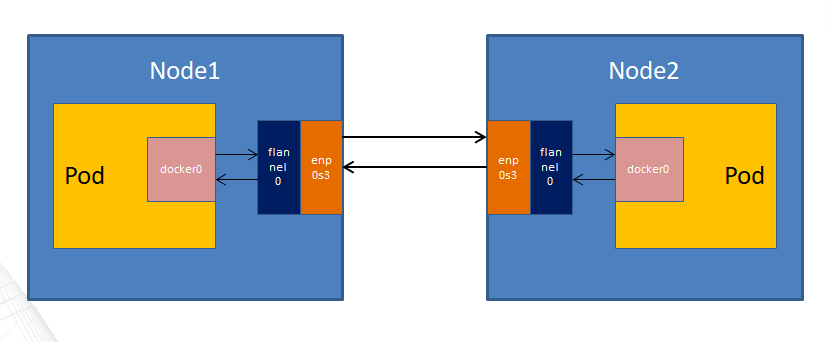
详细示例
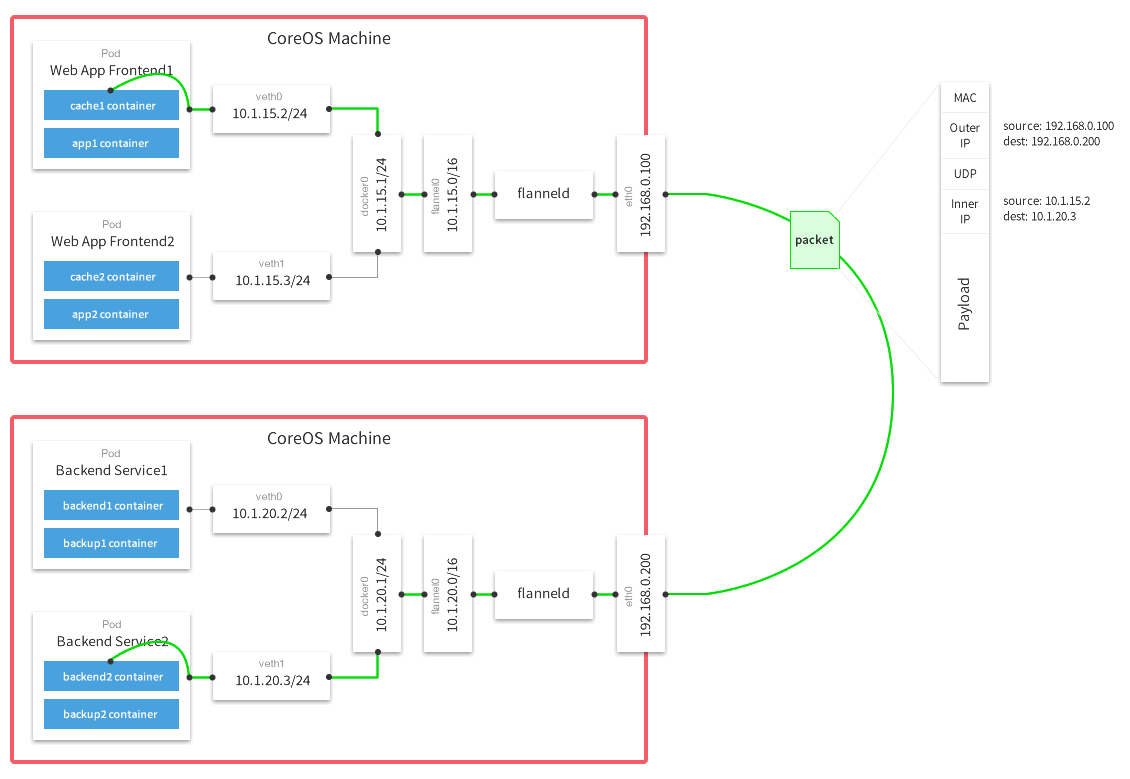
数据从源容器中发出,经所在主机的docker0网卡转发到flannel网卡;
flannel通过etcd维护的路由表将数据发送给目的主机;
源主机的flanneld服务将原数据内容UDP封装和根据自己的路由表传递给目的地节点的flanneld服务;
数据到达后解包,然后直接进入目的节点的flannel网卡;
之后转发到目的主机的docker0网卡;
最后docker0路由到目标容器。
检查网卡
首先查看a/b/c网卡,检查docker0和flannel是否在同一网段。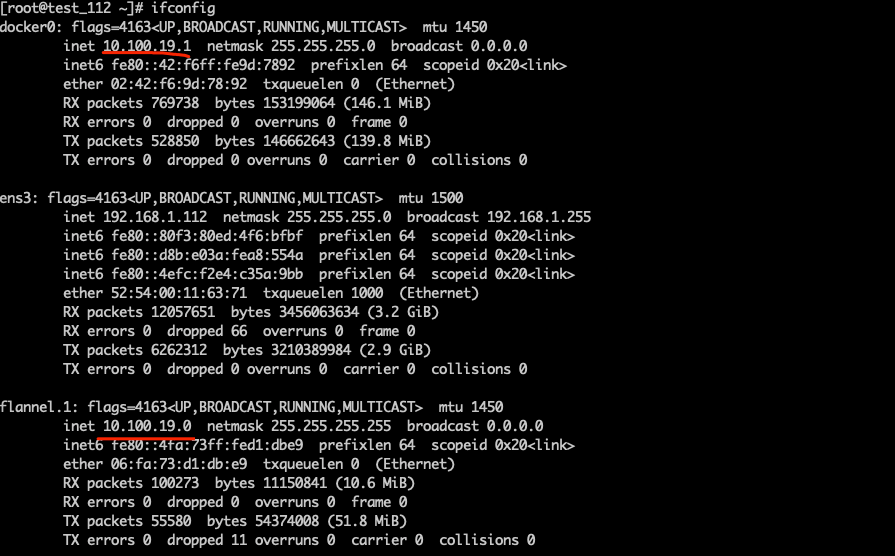
检查结果正常。
检查d节点网卡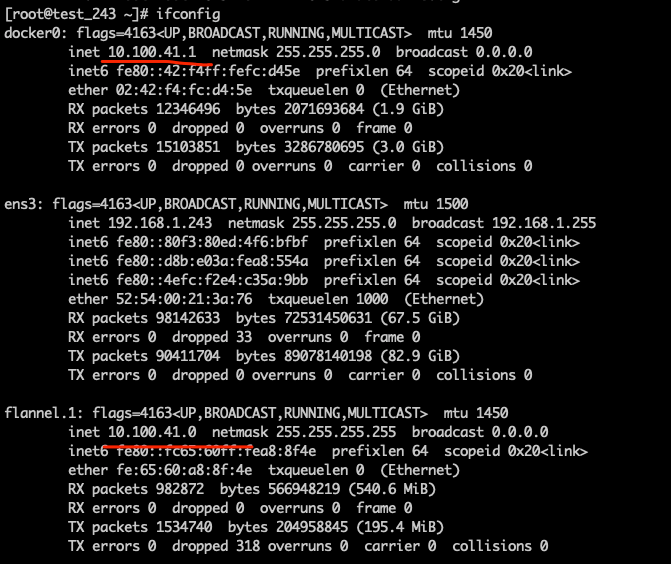
检查结果正常。
检查路由表
查看a/b/c路由表
10.100.0.0 指向flannel
10.100.54.0 指向docker0
192.168.1.0 指向 ens3,局域网地址
查看d路由表
10.100.0.0 指向flannel
10.100.41.0 指向docker0
192.168.1.0 指向 ens3,局域网地址
路由表无异常。
也可以使用下列命令,效果一样:route -n
防火墙
1 | iptables -P FORWARD ACCEPT |
ip forwad
1 | [root@test_243 ~]# sysctl -a|grep ip_forward |
如果没有打开转发,则使用以下方式。
临时
临时生效的配置方式,在系统重启,或对系统的网络服务进行重启后都会失效。这种方式可用于临时测试、或做实验时使用。
方案一
sysctl 命令的 -w 参数可以实时修改Linux的内核参数,并生效。所以使用如下命令可以开发Linux的路由转发功能。
1 | sysctl -w net.ipv4.ip_forward=1 |
方案二
内核参数在Linux文件系统中的映射出的文件:/proc/sys/net/ipv4/ip_forward中记录了Linux系统当前对路由转发功能的支持情况。文件中的值为0,说明禁止进行IP转发;如果是1,则说明IP转发功能已经打开。
1 | echo 1 > /proc/sys/net/ipv4/ip_forward |
永久
在sysctl.conf配置文件中有一项名为net.ipv4.ip_forward的配置项,用于配置Linux内核中的net.ipv4.ip_forward参数。其值为0,说明禁止进行IP转发;如果是1,则说明IP转发功能已经打开。
需要注意的是,修改sysctl.conf文件后需要执行指令sysctl -p后新的配置才会生效。
1 | vim /etc/sysctl.d/99-sysctl.conf |
etcd
检查etcd数据是否正常
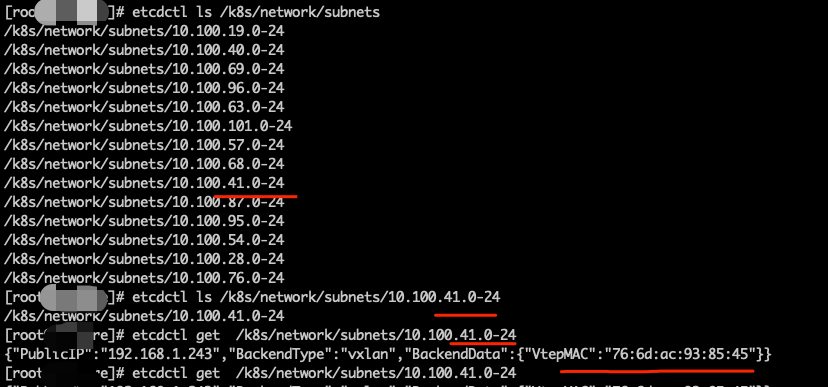 核对网段和Mac地址是否一致。
核对网段和Mac地址是否一致。 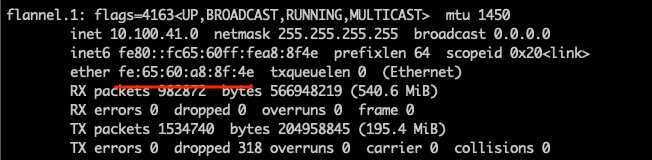 事实证明`10.100.41.0`的网卡和实际的网卡Mac地址并不一致,所以导致源主机没有找到真实的目的主机。
事实证明`10.100.41.0`的网卡和实际的网卡Mac地址并不一致,所以导致源主机没有找到真实的目的主机。 
最后发现,原10.100.41.0的网卡对应的是另外一台历史机器,造成的网卡冲突导致的这一后果。
etcd的基本使用
etcd是一个分布式的、可靠的k-v存储系统,它用于存储分布式系统中的关键数据。在kubernetes中保存集群所有的网络配置和对象的状态信息。在集群中共有两个服务需要用到etcd来协同和存储配置:
- flannel,对于其他网络差价也需要用到etcd;
- kubernetes本身,包括各种对象的状态和元信息配置
获取 集群网络配置
获取子网列表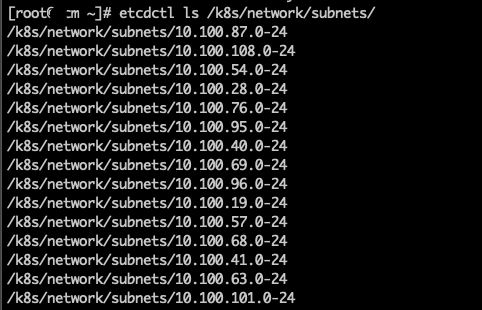
获取主机网卡信息
帮助信息
1 | NAME: |
常见操作
- set 指定某个键的值
1 | [root@xxx ~]# etcdctl set t1 "v1" |
- get获取指定键的值
1 | [root@xxx ~]# etcdctl get t1 |
- rm/rmdir 删除键
1 | [root@scm ~]# etcdctl rm t1 |
网卡地址不在一个网段
在kubernetes集群中某些服务启动顺序是特定的,必须是先启动flannel然后再启动docker。
flannel服务启动时主要做了以下几步的工作:
- 从etcd中获取network的配置信息;
- 划分subnet,并在etcd中进行注册;
- 将子网信息记录到/run/flannel/subnet.env中。
1 | [root@xxx ~]# cat /run/flannel/subnet.env |
之后将会有一个脚本将subnet.env转写成一个docker的环境变量文件/run/flannel/docker
1 | [root@xxx ~]# cat /run/flannel/docker |
然后是Docker服务
Docker服务会根据flannel拿到的网段然后把pod启动在这些网段,这样kubernetes在寻址pod的时候就会找到相应的宿主机,进行通讯。如果Docker服务和Flannel服务没有这种关联关系的化,很可能Docker先用原来的ip段启动,而这个段并没有写到etcd中,导致寻址失败。
kubernetes的高可用
首先简单介绍一下常见的负载均衡类型,主要分为两类:四层和七层。
四层负载均衡是指负载均衡器用IP+Port的方式接收请求,再直接转发到后端对应的服务器上。工作在传输层。客户端和服务器之间建立一次TCP连接,而负载均衡设备至少起类似路由器的转发动作。常见的软件比如LVS。
七层负载均衡是根据虚拟的URL或者主机名来接收请求,经过处理后再转向响应的后端服务器上。工作在应用层,且建立两次连接。
- 客户端到负载均衡器,负载均衡根据消息中的内容来做出负载均衡的决定;
- 然后建立负载均衡器到后端服务器的连接;
负载均衡器需要先代理最终的服务器和客户端建立TCP连接后,才可能接收到客户端发送的真正应用层内容的保温,再根据报文中的特定字段,再加上负载均衡设备的服务器选择方式,决定最终选的服务器。常见的软件比如NGINX。
kubernetes部署架构

kubernetes集群的高可用实际是各个核心组件的高可用。
- apiserver 通过 keepalived+haproxy 实现高可用,当某个节点故障时触发 keepalived vip 转移,haproxy 负责将流量负载到 apiserver 节点;
- controller-manager k8s 内部通过选举方式产生领导者(由 –leader-elect 选型控制,默认为 true),同一时刻集群内只有一个 controller-manager 组件运行,其余处于 backup 状态;
- scheduler k8s 内部通过选举方式产生领导者(由 –leader-elect 选型控制,默认为 true),同一时刻集群内只有一个scheduler组件运行,其余处于 backup 状态;
- etcd 通过运行 kubeadm 方式自动创建集群来实现高可用,部署的节点数为奇数,3节点方式最多容忍一台机器宕机。
多节点的核心点就是需要指向一个核心的地址或者VIP。node请求apiserver时不时直接指向master服务器,而是通过一个虚拟地址来分发到某个master。
常规高可用
方案一、
- haproxy,提供高可用性,负载均衡,基于 TCP 和 HTTP 的代理,支持数以万记的并发连接
- keepalived,是以 VRRP(虚拟路由冗余协议)协议为基础, 包括一个 master 和多个 backup。 master 劫持 vip 对外提供服务。master 发送组播,backup 节点收不到 vrrp 包时认为 master 宕机,此时选出剩余优先级最高的节点作为新的 master, 劫持 vip。keepalived 是保证高可用的重要组件。
haproxy 提供代理后端apiserver的功能,keepalived提供健康检查和切换IP的用途。
方案二、
- nginx
- keepalived
该方案和方案一类似,也是使用代理功能,只不过使用的是NGINX提供的四层转发。
阿里云环境的负载均衡
阿里云云服务器不支持再单独购买 IP,无法安装配置 keepalived,进行负载均衡。如果需要配置负载均衡,可以直接购买负载均衡,进行负载均衡配置。这样就可以省略代理和keepalived的配置,只需要使用slb即可,注意后端服务指向的是master的apiserver的地址和端口。