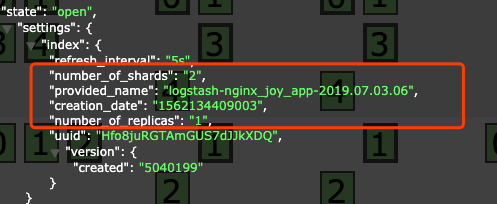
设定副本和切片数量
1
2
| number_of_replicas 是数据备份数,如果只有一台机器,设置为0
number_of_shards 是数据分片数,默认为5,有时候设置为3
|
默认情况下每个索引都会生成5个切片,当然会占用大量磁盘空间。如果是对于安全性要求一般的情况下可以通过设置模板来改变数量。
配置模板文件
- index的名字必须要和指定的json文件中的templete名相匹配,定义的mapping才会生效。logstash的output配置的template_name名可以随便。
- 对于按照日期生成的规则解决办法,就是将template名末尾加一个*号通配符即可:
"template":"logstash-nginx_joy_app*"
1
2
3
4
5
6
7
8
9
10
11
| vim /usr/local/elk/logstash/config/es_nginx.json
{
"template":"logstash-nginx_joy_app*",
"settings":
{
"index.number_of_shards": 2,
"number_of_replicas": 1
}
}
|
配置logstash文件
1
2
3
4
5
6
7
8
9
10
11
12
| output {
if [fields][service] == "nginx_joy_app"{
elasticsearch {
hosts => ["10.110.1.19:9200"]
index => "logstash-nginx_joy_app-%{+YYYY.MM.dd.HH}"
document_type => "logstash-nginx_joy_app"
manage_template => true
template_overwrite => true
template_name => "logstash-nginx_joy_app*"
template => "/usr/local/elk/logstash/config/es_nginx.json"
}
}
|
这样就按照模板规则来生成对应索引了。
![]()
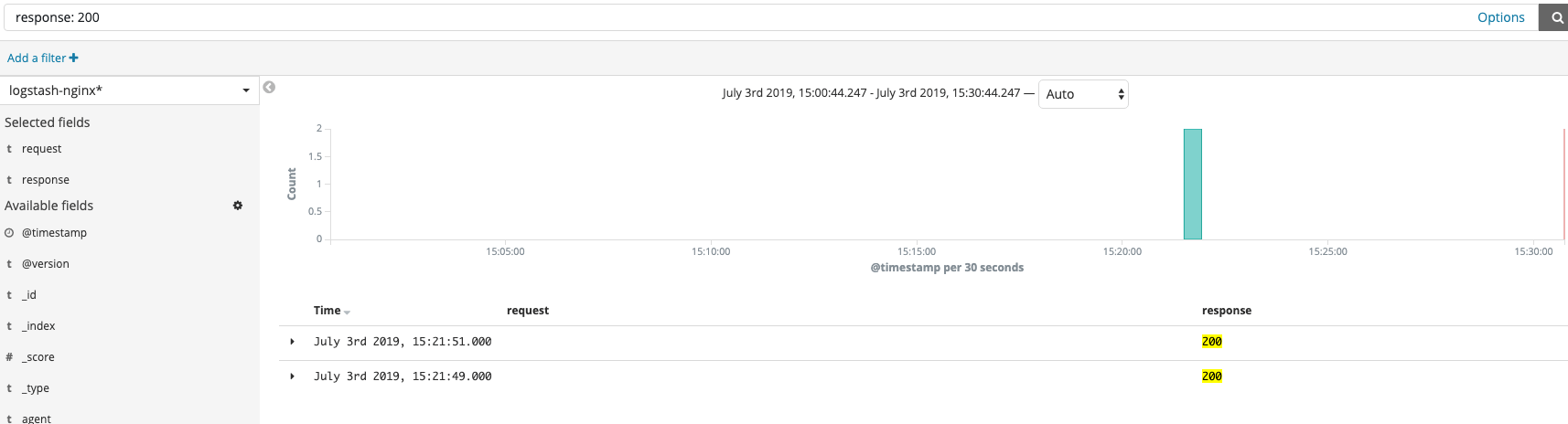
日常语法
按照字段搜索
![]()
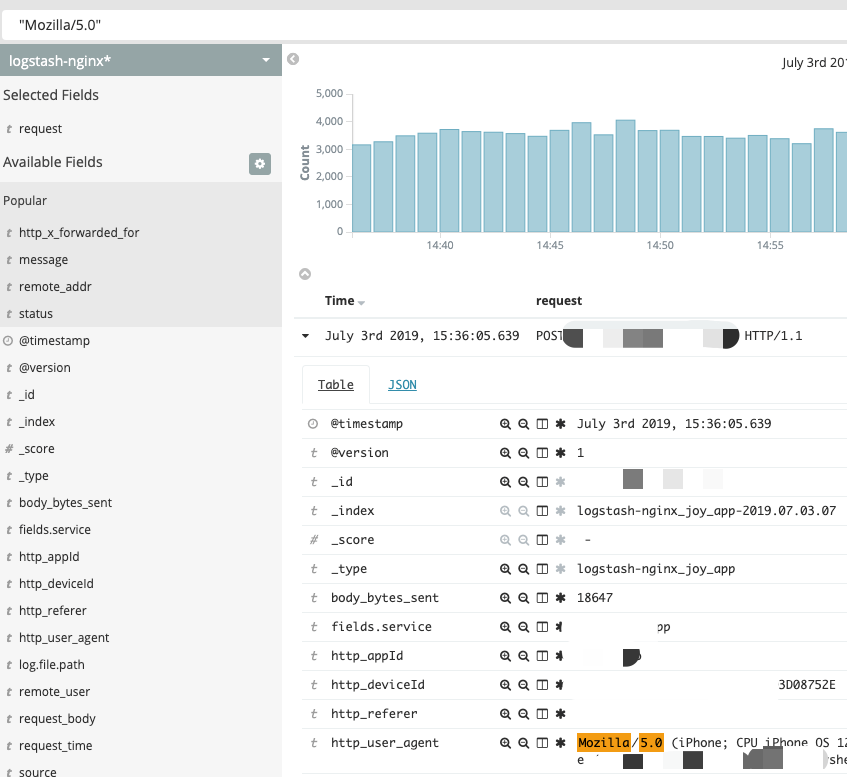
字符串查询
查询一个或者多个的短语
![]()
正则查询
![]()
范围查询
允许一个字段值在某个区间。[] 包含该值,{}不包含。
![]()
布尔查询
布尔运算符(AND,OR,NOT)允许通过逻辑运算符组合多个子查询。
运算符AND/OR/NOT必须大写。
NOT type: mysql
mysql.method: SELECT AND mysql.size: [10000 TO *]
(mysql.method: INSERT OR mysql.method: UPDATE) AND responsetime: [30 TO *]
插件
Logstash中的 logstash-filter-useragent 插件可以帮助我们过滤出浏览器版本、型号以及系统版本。
1
2
3
4
5
6
| if [user_ua] != "-" {
useragent {
target => "agent" #agent将过来出的user agent的信息配置到了单独的字段中
source => "user_ua" #这个表示对message里面的哪个字段进行分析
}
}
|
跨多个es节点的负载均衡
如果想使用kibana访问es集群,那么只需要按照如下操作即可:
- 安装Elasticsearch
- 将节点配置为仅协调节点。在配置文件中配置:
1
2
3
4
5
6
7
| #3。您希望此节点既不是主节点,也不是数据节点,也不是摄取节点,但是
#充当“搜索负载均衡器”(从节点获取数据,
#聚合结果等)
#
node.master:false
node.data:false
node.ingest:false
|
- 配置es节点加入集群
cluster.name:xxxx,注意保持一致 - 将该节点启动后使用kibana调用当前es地址
- kibana.yml 配置多个es地址:
1
2
3
| elasticsearch.hosts:
- http:// elasticsearch1:9200
- http:// elasticsearch2:9200
|
查询
1
2
3
4
5
6
7
8
9
| /_search:所有索引,所有type下的所有数据都搜索出来
/index1/_search:指定一个index,搜索其下所有type的数据
/index1,index2/_search:同时搜索两个index下的数据
/*1,*2/_search:按照通配符去匹配多个索引
/index1/type1/_search:搜索一个index下指定的type的数据
/index1/type1,type2/_search:可以搜索一个index下多个type的数据
/index1,index2/type1,type2/_search:搜索多个index下的多个type的数据
/_all/type1,type2/_search:_all,可以代表搜索所有index下的指定type的数据
|
时区问题
1
2
3
4
5
6
7
8
9
10
11
12
| filter {
ruby {
code => "event.set('index_day', event.timestamp.time.localtime.strftime('%Y.%m.%d.%H'))"
}
}
...
output {
....
index => "logstash-nginx_joy_app-%{index_day}"
}
|
状态检查
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| 1. elasticsearch启动后查看是否启动成功:
curl -XGET"http://$(hostname):9200/_cluster/health?pretty=true"
2. 停止elasticsearch应用:
curl -XPOST "http:// $(hostname):9200/_shutdown"
3. 查看集群健康:
curl $(hostname):9200/_cluster/health?pretty
4. 检查集群状态:
curl $(hostname):9200/_cluster/stats?pretty
5. 节点状态:
curl $(hostname):9200/_nodes/process?pretty
curl $(hostname):9200/_nodes/node1/process?pretty
6. 当你不知道有那些属性可以查看时:
curl '$(hostname):9200/_cat/',会返回可以查看的属性
|
磁盘扩容流程重启节点机器的流程
1
| path.data : /opt/data1,/opt/data2
|
关闭自动平衡
1
2
3
4
5
6
| curl -XPUT "http://xxxx:9200/_cluster/settings" -d'
{
"transient" : {
"cluster.routing.allocation.enable" : "none"
}
}'
|
重启节点
开启平衡
1
2
3
4
5
6
| curl -XPUT "http://xxxx.52:9200/_cluster/settings" -d'
{
"transient": {
"cluster.routing.allocation.enable": "all"
}
}'
|