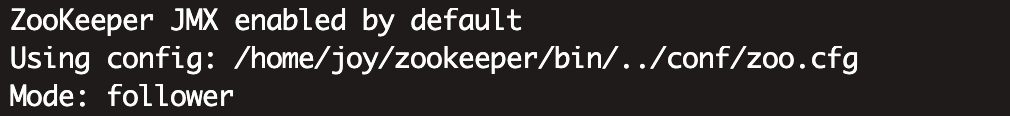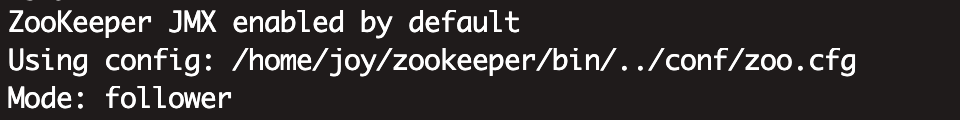Zookeeper 实践
简介
ZooKeeper 是一个开源的分布式协调服务,由雅虎创建,是 Google Chubby 的开源实现。
分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协
调/通知、集群管理、Master 选举、配置维护,名字服务、分布式同步、分布式锁和分布式队列
等功能。
基本概念
角色
一个 ZooKeeper 集群同一时刻只会有一个 Leader,其他都是 Follower 或 Observer。
ZooKeeper 配置很简单,每个节点的配置文件(zoo.cfg)都是一样的,只有 myid 文件不一样。myid 的值必须是 zoo.cfg中server.{数值} 的{数值}部分。
在装有 ZooKeeper 的机器的终端执行 zookeeper-server status 可以看当前节点的 ZooKeeper是什么角色(Leader or Follower)。
ZooKeeper 默认只有 Leader 和 Follower 两种角色,没有 Observer 角色。为了使用 Observer 模式,在任何想变成Observer的节点的配置文件中加入:peerType=observer 并在所有 server 的配置文件中,配置成 observer 模式的 server 的那行配置追加 :observer 。
读写分工
- ZooKeeper 集群的所有机器通过一个 Leader 选举过程来选定一台被称为『Leader』的机器,Leader服务器为客户端提供读和写服务。
- Follower 和 Observer 都能提供读服务,不能提供写服务。两者唯一的区别在于,Observer机器不参与 Leader 选举过程,也不参与写操作的『过半写成功』策略,因此 Observer 可以在不影响写性能的情况下提升集群的读性能
应用场景
ZooKeeper 是一个高可用的分布式数据管理与协调框架。基于对ZAB算法的实现,该框架能够很好地保证分布式环境中数据的一致性。也是基于这样的特性,使得 ZooKeeper 成为了解决分布式一致性问题的利器。
集群配置
环境准备
- 配置jdk
- 配置hosts
- 配置 myid
http://archive.apache.org/dist/zookeeper/
另外一家CDH版本的
http://archive.cloudera.com/cdh5/cdh/5/
配置文件
1 | tickTime=2000 |
配置文件解读
- initLimit:这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 10 个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒
- syncLimit:这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 2*2000=4 秒
- server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
两台部署三台的伪集群示例
1 | ### z1 |
myid
集群模式下还要配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面就有一个数据就是 A 的值,Zookeeper 启动时会读取这个文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是那个 server。
启动节点
1 | bin/zkServer.sh start conf/zoo.cfg |
分别检查节点状态
1 | zookeeper bin/zkServer.sh status conf/zoo.cfg |