Redis集群技术演变
按照需求来分,将实例区分为单机和集群两种类型。
- 单机适合容量和性能要求不高的小型存储
- 集群应对性能和容量要求较高的场景
单机
安全加固
1 | rename-command FLUSHALL "" |
但是注意是否和以下故障切换是否冲突“config”
原生主从(master-slave)
实现高可用,暴露master节点。支持Redis所有指令。
使用Redis 自带的哨兵(Sentinel)集群对实例进行状态监控与 Failover。Sentinel 是 Redis 自带的高可用组件,将 Redis 注册到由多个 Sentinel 组成的 Sentinel 集群后,Sentinel 会对 Redis 实例进行健康检查,当 Redis 发生故障后,Sentinel 会通过 Gossip 协议进行故障检测,确认宕机后会通过一个简化的 Raft 协议来提升 Slave 成为新的 Master。

通常情况仅使用1 个 Slave 节点进行冷备,如果有读写分离请求,可以建立多个Read only slave 来进行读写分离。
- 只读Slave 节点可以按照需求设置 slave-priority 参数为0,防止故障切换时选择了只读节点而不是热备 Slave 节点;
- Sentinel 进行故障切换后会执行 CONFIG REWRITE 命令将SLAVEOF 配置落地,如果 Redis 配置中禁用了 CONFIG 命令,切换时会发生错误,可以通过修改 Sentinel 代码来替换 CONFIG 命令;
- Sentinel Group 监控的节点不宜过多,实测超过 500 个切换过程偶尔会进入 TILT 模式,导致Sentinel 工作不正常,推荐部署多个 Sentinel 集群并保证每个集群监控的实例数量小于 300 个;
- Master 节点应与 Slave 节点跨机器部署,有能力的使用方可以跨机架部署,不推荐跨机房部署 Redis 主从实例;
- Sentinel 切换功能主要依赖 down-after-milliseconds 和failover-timeout 两个参数,down-after-milliseconds 决定了Sentinel 判断 Redis 节点宕机的超时,知乎使用 30000 作为阈值。而 failover-timeout 则决定了两次切换之间的最短等待时间,如果对于切换成功率要求较高,可以适当缩短failover-timeout 到秒级保证切换成功,具体详见Redis 官方文档[2];
- 单机网络故障等同于机器宕机,但如果机房全网发生大规模故障会造成主从多次切换,此时资源发现服务可能更新不够及时,需要人工介入。
Sentinel
Redis 的 Sentinel 系统用于管理多个 Redis 服务器(instance), 该系统执行以下三个任务:
- 监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
优点:
- 基于主从模式,所有主从的优点,sentinel都有
- 主从可以切换,故障可以转移,系统可用性好
- 是主从模式的升级,系统更健壮,可用性更高
缺点:
- 较难支持在线扩容
- 在集群容量达到上限时只能升级机器内存,而不能实现水平扩容
主从同步可能会遇到的问题:
- 端口不通
- 认证失败
| 角色 | IP | 端口 | 其他 |
|---|---|---|---|
| Master,Sentinel1 | 192.168.1.233 | 6379,26379 | |
| slave01,Sentinel2 | 192.168.1.234 | 6379,26379 | |
| slave02,Sentinel3 | 192.168.1.235 | 6379,26379 |
配置redis文件
- 在3台服务器上分别安装Redis。需要注意的是,如果要给Redis设置密码,需要在3个Redis的配置文件中设置相同的密码。
1 | #master |
- 在2个SlaveRedis的配置文件中声明所从属的主数据库。
slaveof 192.168.1.233 6379
1 | daemonize yes |
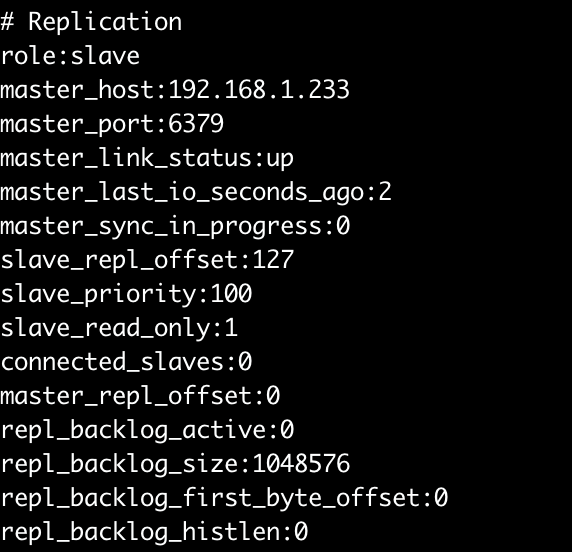
三台机器启动后检查主从状态,数量和状态对的上就没啥问题了。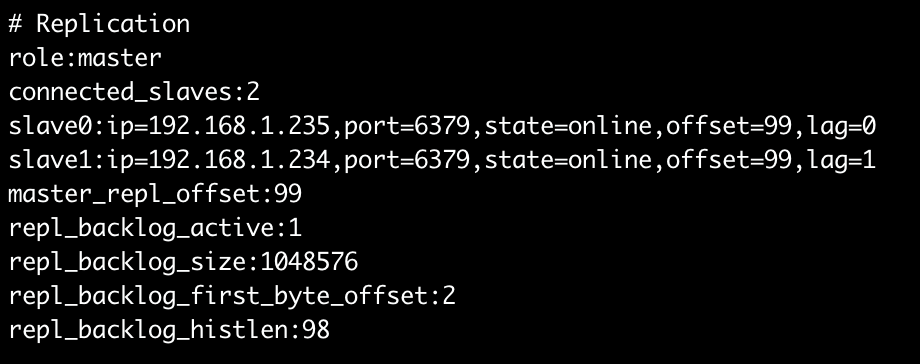
配置sentinel
注意加上认证部分。
配置项解释:
sentinel monitor mymaster 192.168.1.233 6379 2给master取名叫mymaster,2代表集群中有两个sentinel认为master死了的时候,才能真正认为master死了。sentinel集群中通过gossip协互相通信。down-after-millisecondssentinel会向master发送心跳PING来确认master是否存活,如果master在“一定时间范围”内不回应PONG 或者是回复了一个错误消息,那么这个sentinel会主观地(单方面地)认为这个master已经不可用了(subjectively down, 也简称为SDOWN)。而这个down-after-milliseconds就是用来指定这个“一定时间范围”的,单位是毫秒。parallel-syncs不过需要注意的是,这个时候sentinel并不会马上进行failover主备切换,这个sentinel还需要参考sentinel集群中其他sentinel的意见,如果超过某个数量的sentinel也主观地认为该master死了,那么这个master就会被客观地(注意哦,这次不是主观,是客观,与刚才的subjectively down相对,这次是objectively down,简称为ODOWN)认为已经死了。需要一起做出决定的sentinel数量在上一条配置中进行配置。- 在发生failover主备切换时,这个选项指定了最多可以有多少个slave同时对新的master进行同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave处于不能处理命令请求的状态。
配置文件
1 | port 26379 |
1 | port 26379 |
1 | port 26379 |
启动
然后依次启动,之后检查状态
1 | redis-sentinel sentinel.conf |
检查配置文件的变化


发现slave机器上会自动增加其他两个节点的信息。
启动日志
基本命令
- PING :返回 PONG 。
- SENTINEL masters :列出所有被监视的主服务器,以及这些主服务器的当前状态。
- SENTINEL slaves
:列出给定主服务器的所有从服务器,以及这些从服务器的当前状态。 - SENTINEL get-master-addr-by-name
: 返回给定名字的主服务器的 IP 地址和端口号。 如果这个主服务器正在执行故障转移操作, 或者针对这个主服务器的故障转移操作已经完成, 那么这个命令返回新的主服务器的 IP 地址和端口号。 - SENTINEL reset
: 重置所有名字和给定模式 pattern 相匹配的主服务器。 pattern 参数是一个 Glob 风格的模式。 重置操作清楚主服务器目前的所有状态, 包括正在执行中的故障转移, 并移除目前已经发现和关联的, 主服务器的所有从服务器和 Sentinel 。 - SENTINEL failover
: 当主服务器失效时, 在不询问其他 Sentinel 意见的情况下, 强制开始一次自动故障迁移 (不过发起故障转移的 Sentinel 会向其他 Sentinel 发送一个新的配置,其他 Sentinel 会根据这个配置进行相应的更新)。
故障转移
一次故障转移操作由以下步骤组成:
- 发现主服务器已经进入客观下线状态。
- 对我们的当前纪元进行自增(详情请参考 Raft leader election ), 并尝试在这个纪元中当选。
- 如果当选失败, 那么在设定的故障迁移超时时间的两倍之后, 重新尝试当选。 如果当选成功, 那么执行以下步骤。
- 选出一个从服务器,并将它升级为主服务器。
- 向被选中的从服务器发送 SLAVEOF NO ONE 命令,让它转变为主服务器。
- 通过发布与订阅功能, 将更新后的配置传播给所有其他 Sentinel , 其他 Sentinel 对它们自己的配置进行更新。
- 向已下线主服务器的从服务器发送 SLAVEOF 命令, 让它们去复制新的主服务器。
- 当所有从服务器都已经开始复制新的主服务器时, 领头 Sentinel 终止这次故障迁移操作。
每当一个 Redis 实例被重新配置(reconfigured) —— 无论是被设置成主服务器、从服务器、又或者被设置成其他主服务器的从服务器 —— Sentinel 都会向被重新配置的实例发送一个 CONFIG REWRITE 命令, 从而确保这些配置会持久化在硬盘里。
日志说明:
- +sdown 表示哨兵主观认为数据库下线
- +odown 表示哨兵客观认为数据库下线
- +try-failover 表示哨兵开始进行故障恢复
- +failover-end 表示哨兵完成故障修复,其中包括了领头哨兵的选举、备选从数据库的选择等等较为复杂的过程
- +switch-master表示主数据库从51服务器迁移到52服务器
- +slave列出了新的主数据库的2个从数据库,而哨兵并没有彻底清除51服务器的实力信息,这是因为停止的实例有可能会在将来恢复,哨兵会让其重新加入进来
故障转移过程:
- 观察slave节点日志:master故障了
![]() * 发现master故障, * 选举出来233为master * 切换master * 更新sentinel配置文件 * 将原来的master切换为slave,并且定义为down
* 发现master故障, * 选举出来233为master * 切换master * 更新sentinel配置文件 * 将原来的master切换为slave,并且定义为down - 观察sentinel配置文件,master已经切换为新的地址
![]()
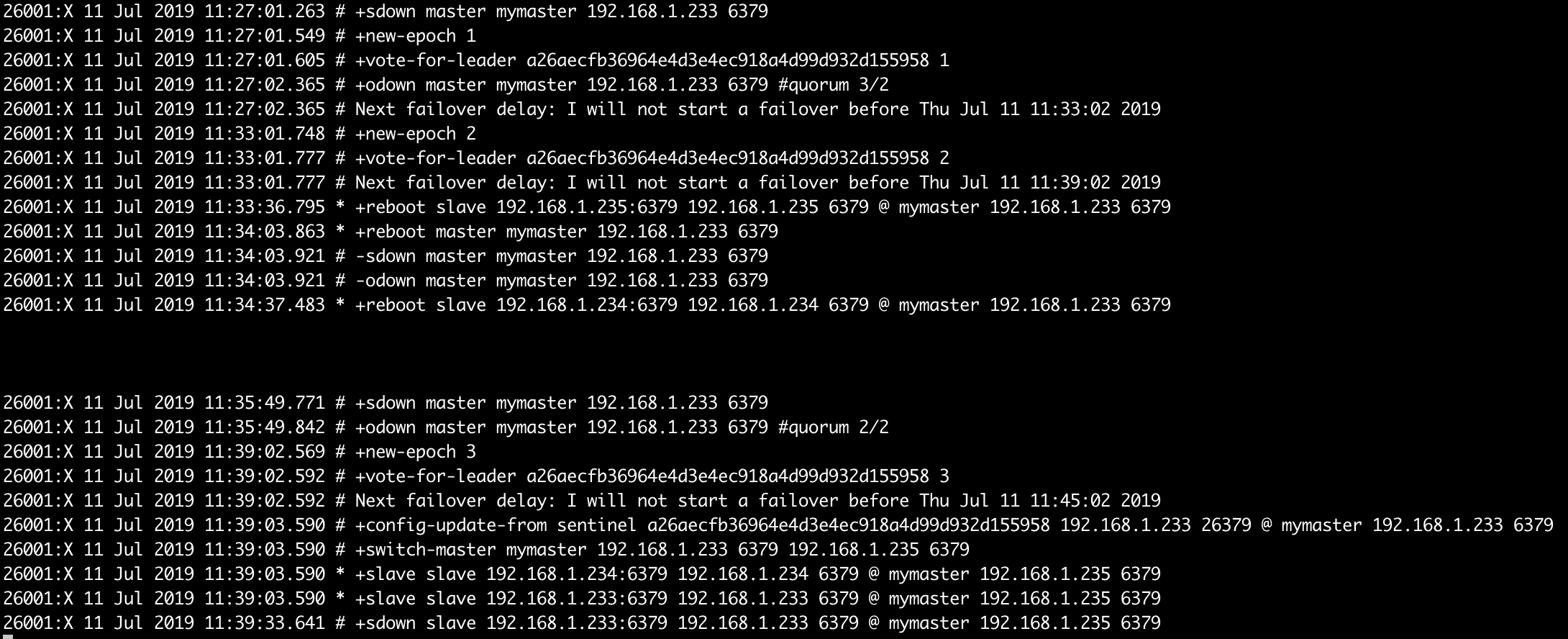 * 发现master故障, * 选举出来233为master * 切换master * 更新sentinel配置文件 * 将原来的master切换为slave,并且定义为down
* 发现master故障, * 选举出来233为master * 切换master * 更新sentinel配置文件 * 将原来的master切换为slave,并且定义为down
之前一直不成功主要的原因就是配置了rename-command "RENAMECONFIG",导致失败的,这个要多注意一下。
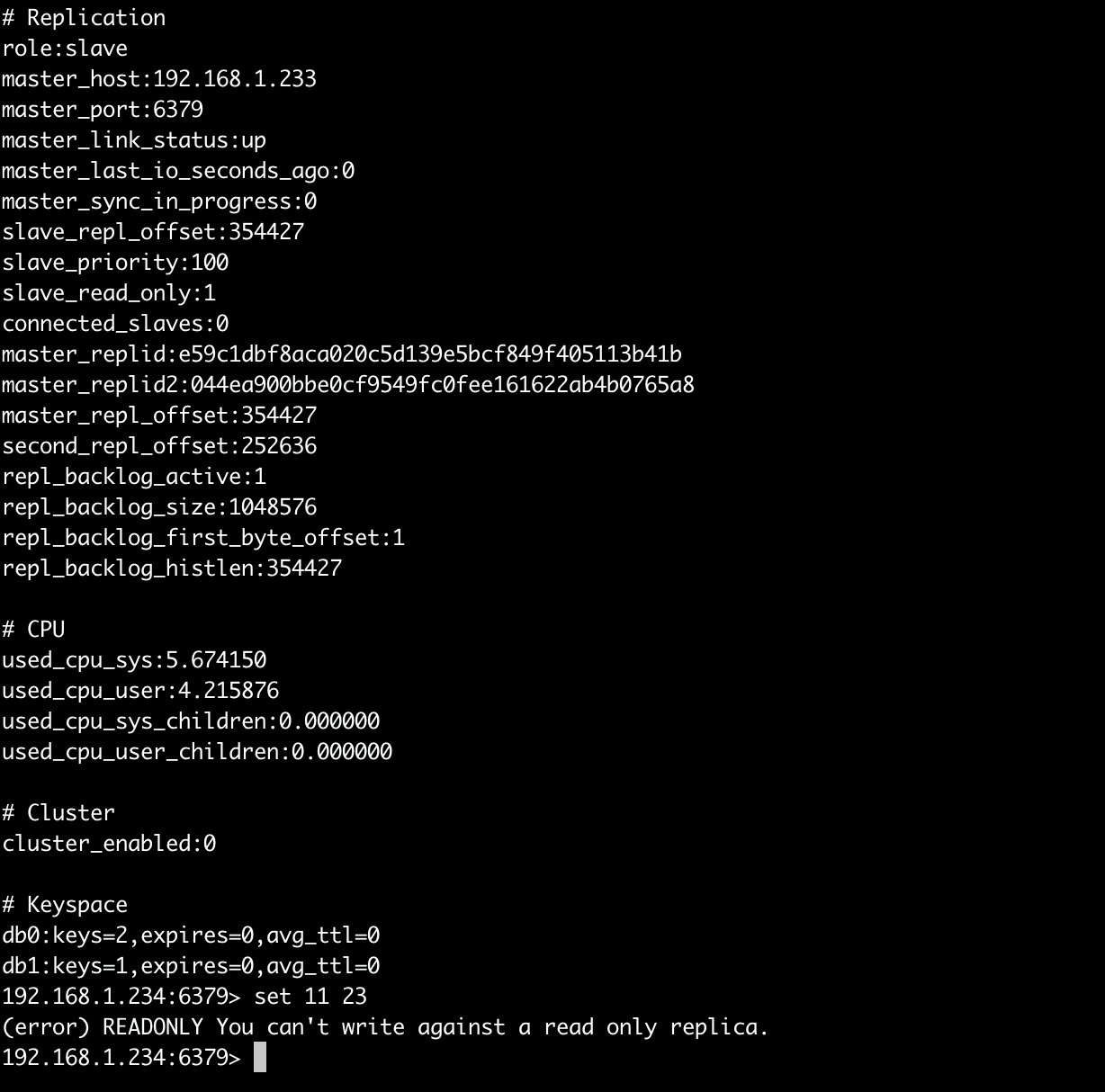
常见问题
- slave不能写
![]()
访问sentinel集群
以Python为例,程序通过sentinel提供的端口进行访问,获取master地址进行写操作,读操作默认是轮询。
1 | Python 2.6.6 (r266:84292, Jan 22 2014, 09:42:36) |
集群(Cluster)
cluster的出现是为了解决单机Redis容量有限的问题,将Redis的数据根据一定的规则分配到多台机器。对cluster的一些理解:
- cluster可以说是sentinel和主从模式的结合体,通过cluster可以实现主从和master重选功能,所以如果配置两个副本三个分片的话,就需要六个Redis实例。
- 因为Redis的数据是根据一定规则分配到cluster的不同机器的,当数据量过大时,可以新增机器进行扩容。这种模式适合数据量巨大的缓存要求,当数据量不是很大使用sentinel即可。
简介
Redis集群是一个可以在多个Redis节点之间进行数据共享的设施。
Redis集群不支持需要同时处理多个键的命令,因为在执行这些命令的时候需要在多个Redis节点之间移动数据,会降低集群性能。
Redis集群通过分区来提供一定程度的可用性:即使集群中有一部分节点失效,集群也可以继续处理命令请求。
优点:
- 将数据自动切分到多个节点的能力
- 当部分节点失效的时候,集群仍然可以继续处理命令请求
数据共享
一个集群包含16384个哈希槽,数据库中的每个键都属于这16384个哈希槽的其中一个。
每个节点负责处理一部分哈希槽,比如一个集群有三个节点,就均分为3大块哈希槽。
这种哈希槽的处理方式使用处更容易或者更快的添加删除节点。比如
- 增加节点。ABC只需要将部分哈希槽移动到新的D就可以了
- 删除节点,ABCD只需要将要删除的D节点的哈希槽移动到ABC就可以了
集群中的主从复制
集群中的主从复制功能:集群中的每个节点都有N个复制品,其中一个复制品为主节点,其余的为从节点。
比如之前的B节点下线了,那么集群中会丢失部分哈希槽。但是如果创建集群的时候为B节点添加了从节点B1,那么在B下线的时候,B1就会为新的主节点,取代处理之前对应的哈希槽。这样集群就会正常运作了。
集群一致性保证
集群不保证数据的强一致性,在特定条件下,集群可能会丢失已经被执行过的写命令。
使用异步复制是丢失写命令的一个原因,示例如下:
- 客户端向主节点B发送写的命令
- 主节点B执行写命令,并向客户端放回命令回复
- 主机点B
部署
配置文件
创建三个目录,然后依次修改端口,之后发送到其他节点机器。
1 | daemonize yes |
启动命令
1 | 7000/bin/redis-server 7000/cluster.conf |
1 创建集群
对于5.0以前的版本:
1 | /usr/local/redis_cluster/7000/bin/redis-trib.rb create --replicas 2 192.168.1.233:7000 192.168.1.233:7001 192.168.1.233:7002 192.168.1.234:7000 192.168.1.234:7001 192.168.1.234:7002 192.168.1.235:7000 192.168.1.235:7001 192.168.1.235:7002 |
对于5.0的版本:
1 | /usr/local/redis_cluster/7000/bin/redis-cli --cluster create --cluster-replicas 2 192.168.1.233:7000 192.168.1.233:7001 192.168.1.233:7002 192.168.1.234:7000 192.168.1.234:7001 192.168.1.234:7002 192.168.1.235:7000 192.168.1.235:7001 192.168.1.235:7002 |
如果使用了错误的版本命令,会有下面的警告信息。
1 | [root@base_233 redis_cluster]# /usr/local/redis_cluster/7000/bin/redis-trib.rb create --replicas 2 192.168.1.233:7000 192.168.1.233:7001 192.168.1.233:7002 192.168.1.234:7000 192.168.1.234:7001 192.168.1.234:7002 192.168.1.235:7000 192.168.1.235:7001 192.168.1.235:7002 |
redis 5.0 放弃redis-trib.rb,使用
redis-cli --cluster create创建集群。也就是说5.0以后所有的集群操作都是通过redis-cli --cluster来执行的。
创建集群后会提示是否能更新以上的配置?选择yes
修复集群
1 | /usr/local/redis_cluster/7000/bin/redis-cli --cluster check 192.168.1.233:7001 |
监控
https://github.com/ZhuoRoger/redismon
or
https://github.com/iambocai/falcon-monit-scripts
备份机制
AOF
每秒或者每次写操作,安全,速度不够快,也存在丢失1秒的可能。可以在从机器上开启。
RDB
快照,定时,或者数量改变时,存储到一个二进制文件。容易恢复,文件小,但是存在不完整的可能。
主库开启RDB,每天
从库开启AOF,
如果只配置AOF,重启时加载AOF文件恢复数据;
如果同时 配置了RBD和AOF,启动是只加载AOF文件恢复数据;
如果只配置RBD,启动是讲加载dump文件恢复数据。
参考资料
http://doc.redisfans.com/topic/sentinel.html
sentinel客户端使用参考
sentinel和cluster的对比