前言 在执行IO密集型任务的时候,程序经常会因为等待IO而阻塞。比如平时使用的requests库来进行请求接口,如果响应过慢,程序会一直等待响应,最后导致抓取数据的效率低下。为了解决这一问题,来研究一下异步协程加速的方法。
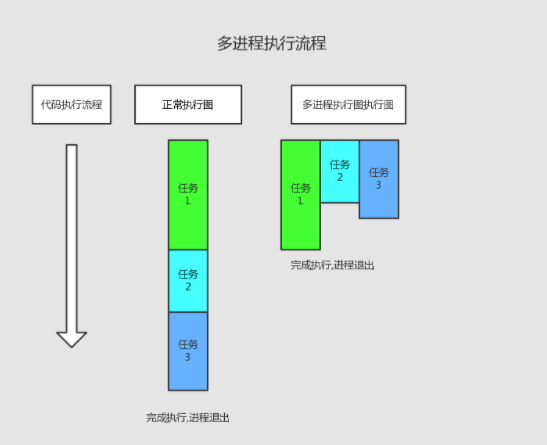
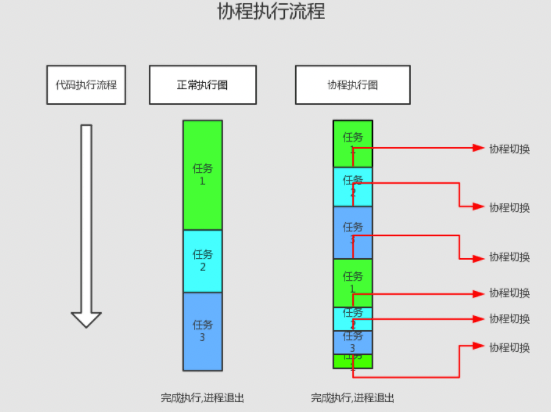
概念 阻塞。阻塞状态是指程序未得到所需计算资源被挂起的状态。程序在等待某操作期间,自身无法继续干别的事。常见的阻塞形式:网络I/O阻塞、磁盘IO/阻塞、用户输入阻塞等。 非阻塞。程序在等待某操作过程中,自身不被阻塞,可以继续运行干别的事,则成该程序在该操作上非阻塞的。 非阻塞的存在是因为阻塞存在,正因为某个操作阻塞导致的耗时和效率低下,因此我们才要把它变味非阻塞的。 同步。不同的程序为了完成某个任务,在执行过程中需要依靠某种同喜方式协调一致,称这些程序单元是同步执行的,比如商品库存。 异步。为了完成某个任务,不同程序之间过程无需通信协调,也能完成任务的方式,不相关的程序单元之间是可以异步的。比如爬虫网页。 多进程。就是利用CPU多核的优势,在同一时间并行的执行多个任务,可以极大的提高效率。 协程,Coroutine,又称微线程,是一种用户态的轻量级线程。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复之前保存的寄存器上下文和栈。因此协程能保留上一次调用时的状态,即局部状态的一个特定组合,每次过程重入时,就相当于进入上一次调用的状态。协程本质上是个单线程,相对于多进程来说,无需线程的上下文切换的开销,无需原子操作锁定及同步的开销。可以使用的场景,比如在网络爬虫的场景,发出一个请求之后,需要等待一定的实际才能得到响应。但是在等待过程中,程序可以做一些其他的事情,等到响应后再切回来继续处理,这样可以充分利用CPU和其他资源,也就是协程的优势所在。 执行顺序的对比
协程的用法 协程相关的概念:
event_loop 事件循环,相当于一个无限循环,可以把一些函数注册到这个事件循环上,当满足条件时,就会调用对应的处理方法。 coroutine 协程,在 Python 中常指代为协程对象类型,可以将协程对象注册到事件循环中,会被事件循环调用。使用 async 关键字来定义一个方法,在调用时不会立即被执行,而是先放回一个协程对象。 task 任务,是对协程对象的进一步封装,包含了任务的所有状态。 future 代表将来执行或没有执行任务的任务的结果,和task没有本质的区别。 定义协程 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import asyncioasync def get_number (x ): print ('Number:' , x) return x if __name__ == '__main__' : coroutine = get_number(1 ) print ('Coroutine:' , coroutine) print ('After calling execute' ) loop = asyncio.get_event_loop() loop.run_until_complete(coroutine) print ('After calling loop' ) Coroutine : <coroutine object get_number at 0x10e049f40 >After calling execute Number: 1 After calling loop
执行过程的分析:
引入 asyncio ,这样才可以使用 async 和 await; 然后使用async定义一个方法,方法接收一个数字的参数,该方法执行后会打印数字; 随后调用这个方法,但是并没有执行,而是返回一个coroutine 协程对象; 之后我们使用get_event_loop方法创建一个事件循环loop,并调用了loop对象的run_until_complate方法将协程注册到事件循环loop中,然后启动; 最后看到了输出结果。 可见,async 定义的方法机会变成一个无法直接运行的coroutine对象,必须注册到事件循环中才可以执行。上文中提到的task,是对coroutine对象的进一步封装,比coroutine对象多了允许状态,比如running、fiished等,可以通过这些状态来获取协程对象的执行情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import asyncioasync def get_number (x ): print ('Number:' , x) return x if __name__ == '__main__' : coroutine = get_number(1 ) print ('Coroutine:' , coroutine) print ('After calling execute' ) loop = asyncio.get_event_loop() task = loop.create_task(coroutine) print ('Task:' , task) loop.run_until_complete(task) print ('Task:' , task) print ('After calling loop' ) Coroutine : <coroutine object get_number at 0x10e38df40 >After calling execute Task: <Task pending name='Task-1' coro=<get_number() running at /Users/medivh/tools/test_async.py:45 >> Number: 1 Task: <Task finished name='Task-1' coro=<get_number() done, defined at /Users/medivh/tools/test_async.py:45 > result=1 > After calling loop
这里定义loop对象后,接着调用了create_task方法将coroutine对象转化为了task对象,随后的输出发现是pending状态。接着将task对象添加到事件循环中得到执行,随后再输出,就变成了finished。并且同时result变成了1,也就是get_number方法的返回结果。
另外,还有一种定义task对象的方式,直接通过asyncio的ensure_future()方法,返回的也是task对象,就不需要借助loop来定义。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import asyncioasync def get_number (x ): print ('Number:' , x) return x if __name__ == '__main__' : coroutine = get_number(1 ) print ('Coroutine:' , coroutine) print ('After calling execute' ) task = asyncio.ensure_future(coroutine) print ('Task:' , task) loop = asyncio.get_event_loop() loop.run_until_complete(task) print ('Task:' , task) print ('After calling loop' ) Coroutine : <coroutine object get_number at 0x10c19ff40 >After calling execute Task: <Task pending name='Task-1' coro=<get_number() running at /Users/medivh/tools/test_async.py:48 >> Number: 1 Task: <Task finished name='Task-1' coro=<get_number() done, defined at /Users/medivh/tools/test_async.py:48 > result=1 > After calling loop
绑定回调 可以给某个task搬到回调方法,示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import asyncioimport requestsasync def get_status (): url = 'https://www.baidu.com' status = requests.get(url).status_code return status def callback (task ): print ('Status:' , task.result()) if __name__ == '__main__' : coroutine_obj = get_status() task = asyncio.ensure_future(coroutine_obj) task.add_done_callback(callback) print ('Task:' , task) loop = asyncio.get_event_loop() loop.run_until_complete(task) print ('Task:' , task) Task: <Task pending name='Task-1' coro=<request() running at /Users/medivh/github/mercury/tools/test_async.py:69 > cb=[callback() at /Users/medivh/tools/test_async.py:75 ]> Status: 200 Task: <Task finished name='Task-1' coro=<request() done, defined at /Users/medivh/tools/test_async.py:69 > result=200 >
代码说明:
调用add_done_callback方法,将callback方法传递给封装好的task对象; task执行完毕后调用callback方法; task对象同时作为参数传递给callback方法,调用task对象的result方法就可以获取返回结果。 其实,不用回方法,直接在task运行完毕后也可以直接调用result方法获取结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import asyncioimport requestsasync def get_status (): url = 'https://www.baidu.com' status = requests.get(url).status_code return status if __name__ == '__main__' : coroutine_obj = get_status() task = asyncio.ensure_future(coroutine_obj) print ('Task:' , task) loop = asyncio.get_event_loop() loop.run_until_complete(task) print ('Task:' , task) print ('Task Result:' , task.result()) Task: <Task pending name='Task-1' coro=<get_status() running at /Users/medivh/tools/test_async.py:69 >> Task: <Task finished name='Task-1' coro=<get_status() done, defined at /Users/medivh/tools/test_async.py:69 > result=200 > Task Result: 200
多任务协程 对于想执行多次请求的方案,可以定义一个task列表,然后使用asyncio的wait方法即可执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import asyncioimport requestsasync def get_status (): url = 'https://www.baidu.com' status = requests.get(url).status_code return status if __name__ == '__main__' : tasks = [asyncio.ensure_future(get_status()) for _ in range (5 )] print ("Tasks: " , tasks) loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.wait(tasks)) for task in tasks: print ("Task Result:" , task.result()) Tasks: [<Task pending name='Task-1' coro=<get_status() running at /Users/medivh/github/mercury/tools/test_async.py:69 >>, <Task pending name='Task-2' coro=<get_status() running at /Users/medivh/github/mercury/tools/test_async.py:69 >>, <Task pending name='Task-3' coro=<get_status() running at /Users/medivh/github/mercury/tools/test_async.py:69 >>, <Task pending name='Task-4' coro=<get_status() running at /Users/medivh/github/mercury/tools/test_async.py:69 >>, <Task pending name='Task-5' coro=<get_status() running at /Users/medivh/github/mercury/tools/test_async.py:69 >>] Task Result: 200 Task Result: 200 Task Result: 200 Task Result: 200 Task Result: 200
代码说明:
for循环创建5个task,组成list; 把list首先传给asyncio的wait方法,然后注册到事件循环中; 发起5个任务; 输出任务结果。 协程实现 前面的代码都是以网络请求为例,都是耗时的等待的操作,因为在请求网页后需要等待页面响应并返回结果。耗时的等待操作一般都是IO操作,比如文件读写、网络请求等,而协程对于处理这种操作具有很大优势。往往可以在需要等待的时候,程序可以暂时挂起,转而执行其他的操作,从而避免等待一个程序而耗费过多的时间,达到充分利用资源的目的。
代码示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import asyncioimport requestsimport timeasync def get_status (): url = 'http://127.0.0.1/welcome' print ('waiting for {} {}' .format (url,time.time())) status = requests.get(url).status_code return status if __name__ == '__main__' : start = time.time() tasks = [asyncio.ensure_future(get_status()) for _ in range (5 )] loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.wait(tasks)) end = time.time() print ('Cost time:' , end - start) waiting for http://127.0 .0 .1 /welcome 1658818769.805218 waiting for http://127.0 .0 .1 /welcome 1658818770.0085208 waiting for http://127.0 .0 .1 /welcome 1658818770.101907 waiting for http://127.0 .0 .1 /welcome 1658818770.1906009 waiting for http://127.0 .0 .1 /welcome 1658818770.262319 Cost time: 0.5311617851257324
事实上和正常的请求耗时相差不大,几乎是依次执行的。其实出现这种情况是因为要实现异步处理,必须得有挂起的操作,当一个任务需要等待IO结果的时候,可以挂起当前任务,转而去执行其他任务。
接下来了解一下await的用法,使用await可以将耗时等待的操作挂起,让出控制权。当协程执行的时候遇到await,事件循环就会将本协程挂起,转而执行其他的协程,知道其他的协程挂起或执行完毕。然后,将代码改造一下。
如果直接改造上文代码,会出现以下提示Class 'int' does not define '__await__', so the 'await' operator cannot be used on its instances。这是因为await后必须符合以下对象:
一个原生coroutine对象 一个有types.coroutine()修饰的生成器,这个生成器可以返回coroutine对象 一个包含await方法的对象返回的一个迭代器 接下来进行一次尝试,用async把请求的方法改造成coroutine对象:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import asyncioimport requestsimport timeasync def get_status (url ): return requests.get(url).status_code async def get_result (): url = 'http://127.0.0.1/welcome' print ('waiting for {} {}' .format (url, time.time())) status = await get_status(url) return status if __name__ == '__main__' : start = time.time() tasks = [asyncio.ensure_future(get_result()) for _ in range (50 )] loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.wait(tasks)) end = time.time() print ('Cost time:' , end - start) waiting for http://127.0 .0 .1 /welcome 1658819455.563387 waiting for http://127.0 .0 .1 /welcome 1658819455.612329 waiting for http://127.0 .0 .1 /welcome 1658819455.662548 Cost time: 3.005825996398926
输出的结果证明这种方式不可行,并没有达到真正的异步。这里使用一个支持异步请求的库——aiohttp,利用它和asyncio配合可以方便的实现异步请求操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 pip install apiohttp import asyncioimport timeimport aiohttpasync def get_status (url ): session = aiohttp.ClientSession() response = await session.get(url) result = await response.text() await session.close() return result async def get_result (): url = 'http://127.0.0.1/api/afk/pod?current=1&pageSize=100' status = await get_status(url) return status if __name__ == '__main__' : start = time.time() tasks = [asyncio.ensure_future(get_result()) for _ in range (10 )] loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.wait(tasks)) end = time.time() print ('Cost time:' , end - start) Cost time: 1.1510028839111328
请求耗时直接缩短到1秒左右。
使用await,后面跟get方法,在执行10个协程的时候,遇到了await,就会将当前协程挂起,转而执行其他协程,直到其他协程也挂起或执行完毕,再进行下一个协程的执行; 开始运行的时候,事件循环会运行第一个task,第一个task执行遇到await跟着的get方法后,被挂起。但这个get方法第一步的执行是非阻塞的,挂起后立刻被环行,创建了ClientSession对象,接着遇到第二个await,调用了session.get()请求方法,然后就被挂起。由于请求耗时较久,所以一直没有被唤醒; 事件循环会寻找当前为被挂起的协程继续执行,于是转而执行第二个task。之后,依次执行了第10个task的session.get()方法后,全部的task被挂起。 所有task处于挂起状态,等待响应。1秒后,所有请求几乎同时有了响应,然后这10个task都被唤醒继续执行,输出请求结果。 接下来尝试不同量级的task,输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Cost time: 1.0380501747131348 Cost time: 1.143162727355957 Cost time: 3.379934787750244 Cost time: 5.655962705612183 Cost time: 9.78205680847168 Cost time: 9.797142028808594
最后的运行时间基本都在10秒内,200个task开始就会出现502情况,当然这个完全在于后端服务的问题。但是100个task以内的时候,时间都是很接近的。
和单进程、多进程对比 单进程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import requestsimport timedef get_page (): url = 'http://127.0.0.1/api/afk/pod?current=1&pageSize=100' result = requests.get(url).status_code return result if __name__ == '__main__' : start = time.time() for _ in range (100 ): get_page() end = time.time() print ('Cost time:' , end - start) Cost time: 106.35312700271606
多进程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import requestsimport timeimport multiprocessingdef get_page (_ ): url = 'http://127.0.0.1/api/afk/pod?current=1&pageSize=100' result = requests.get(url).status_code return result if __name__ == '__main__' : start = time.time() pool = multiprocessing.Pool(8 ) pool.map (get_page, range (100 )) end = time.time() print ('Cost time:' , end - start) Cost time: 16.823662996292114
8核CPU执行时间为16.8秒,远大于协程的5.6秒。
多线程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import timeimport threadingdef get_page (): url = 'http://127.0.0.1/api/afk/pod?current=1&pageSize=100' result = requests.get(url).status_code return result if __name__ == '__main__' : start = time.time() threads = [] for i in range (200 ): t = threading.Thread(target=get_page) threads.append(t) for t in threads: t.setDaemon(True ) t.start() for t in threads: t.join() end = time.time() print ('Cost time:' , end - start) Cost time: 10.563114881515503
多线程:
1 2 Cost time: 1.160654067993164
回顾 前面讲了那么多,是不是有些内容值得思考一下呢?现在回过头来再总结一下。
进程 进程是操作系统对一个正在运行的程序的一种抽象,进程是资源分配的最小单位。
线程 有了多进程,为什么还要线程?原因如下:
进程直接的信息难以共享,父子进程并未共享内存,需要进程间通信,性能开销大 创建进程的性能开销较大。 进程由多个线程组成,一个进程可以由多个线程的执行单元组成。每个线程都在运行进程的上下文中,共享着同样的代码和全局数据。多个线程比多进程之间更容易共享数据,在上下文切换中一般比进程更高效,原因如下:
线程间能够快速、方便共享数据 创建线程的速度比创建进程快10倍以上 协程 协程是用户态的线程。协程的优势:
节省CPU。避免系统内核级的线程频繁切换,造成CPU的浪费。协程是用户态的线程,用户可以自行控制协程的创建和销毁,极大程度上避免了系统级线程上下文切换造成的资源浪费。 节约内存。64位的Linux系统中,一个线程需要分配8MB栈内存和64MB堆内存。系统内存的制约导致无法开启更多线程的并发。而协程只需要KB级别,可以轻松达到几十万。 稳定性。线程之间通过内存来共享数据,这就会导致一个问题,比如一个线程出错时,进程中的所有线程都会跟着崩溃。 开发效率。开发过程中,可以方便的把一些耗时的IO操作异步化,比如些写文件、耗时IO请求等。 总之,协程的本质是用户态下的线程.
用一个形象的例子:
进程就像一家餐馆,餐馆有多个服务员,每个餐桌是要完成的任务。单进程,对应一家餐馆; 多进程,增加了N家餐馆,接待的客人多了,成本也上去了; 多线程。一家餐馆,来一桌客人安排一个服务员; 协程。一家餐馆只安排一个服务员,A点菜,就去B服务,A点完了就再回到A这。B还没点完就去C那,依次类推,直到所有人都吃上饭。