1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
|
"""
@time:2022/09/29
@file:17k.com.py
@author:medivh
@IDE:PyCharm
"""
import asyncio
import aiohttp
import aiofiles
import shutil
from lxml import etree
import time
from utils import random_useragent
import os
from gevent import monkey
monkey.patch_all()
headers = {
"User-Agent": random_useragent(),
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
}
async def download_target(url, i, book_title, sem):
async with sem:
async with aiohttp.ClientSession() as session:
async with session.get(url, headers=headers) as resp:
html = etree.HTML(await resp.content.read())
try:
body_html = html.xpath('//div[@class="readAreaBox content"]')[0]
except Exception as e:
print('body获取失败', e, url)
title = body_html.xpath('./h1/text()')[0]
if i < 10:
num = '000' + str(i)
elif i < 100:
num = '00' + str(i)
elif i < 1000:
num = '0' + str(i)
file_name = './novel/{}/{}.txt'.format(book_title, num)
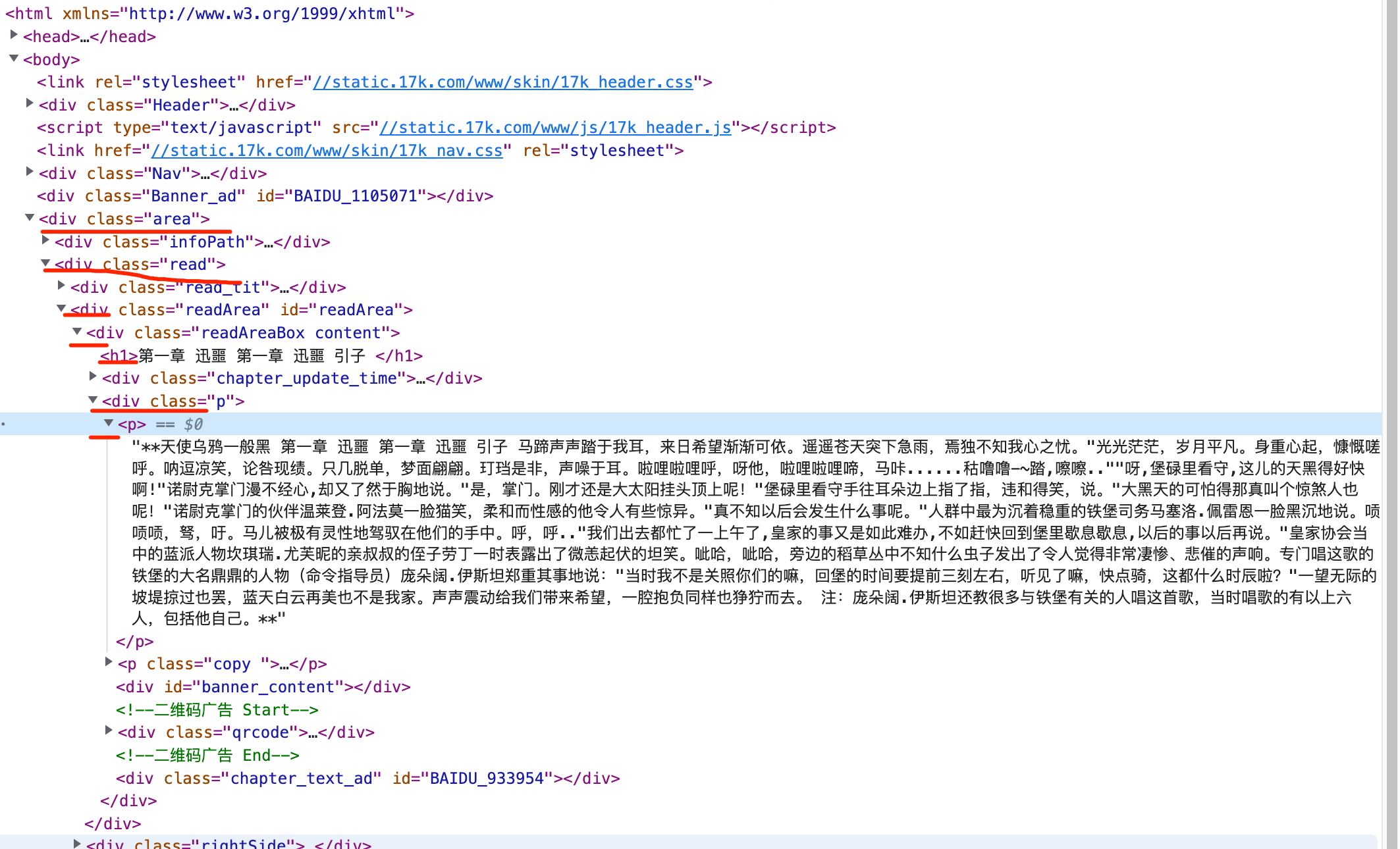
content_html = body_html.xpath('./div[@class="p"]/p')
content = [i.xpath('./text()')[0] for i in content_html if i.xpath('./text()')]
try:
content.remove(content[-1])
except Exception as e:
print(e, url)
content.insert(0, title)
content.append('该章节存在问题,已经被锁定,暂时无法查看') if len(content) == 1 else content.append(' ')
async with aiofiles.open(file_name, 'a+') as f:
await f.write("\n".join(content))
all_book_list = list()
async def get_page_urls(url, sem):
async with sem:
async with aiohttp.ClientSession() as session:
async with session.get(url, headers=headers) as resp:
html = etree.HTML(await resp.content.read())
urls = []
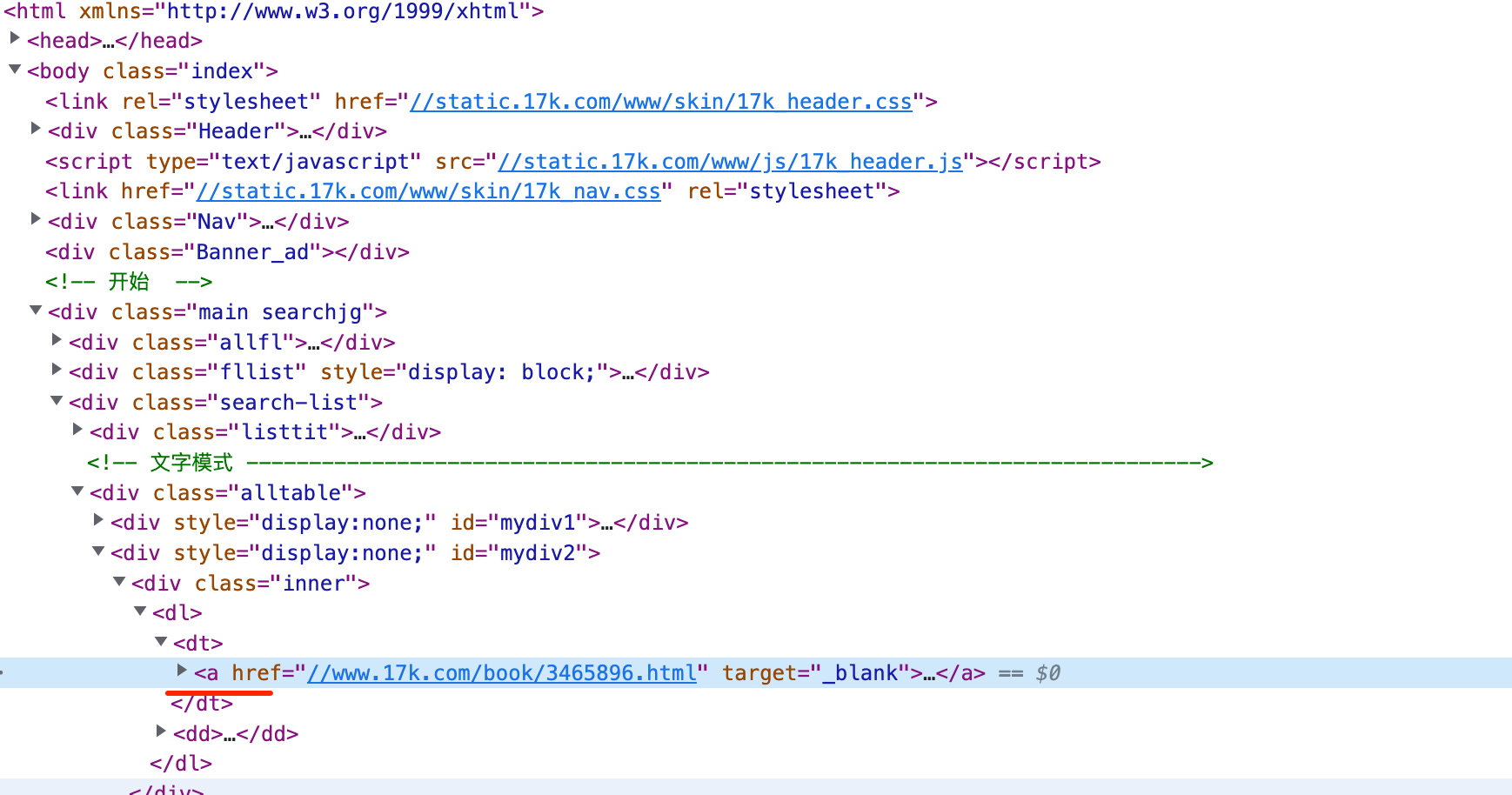
title_of_book = html.xpath('//div[@class="Main List"]/h1/text()')[0]
print(title_of_book)
td_html = html.xpath('//div[@class="Main List"]/dl[1]/dd[1]/a/@href')
for i in td_html:
url = 'https://www.17k.com{}'.format(i)
urls.append(url)
print('共获取 {} 章节'.format(len(urls)))
book_info = {
'title': title_of_book,
'urls': urls
}
all_book_list.append(book_info)
all_book_url = list()
async def get_book_url(url, sem):
async with sem:
async with aiohttp.ClientSession() as session:
async with session.get(url, headers=headers) as resp:
html = etree.HTML(await resp.content.read())
try:
table_html = html.xpath('//tbody/tr[position()>2]')
for i in table_html:
url = i.xpath('./td[3]/span/a/@href')[0].replace('book', 'list')
url = 'https:' + url
all_book_url.append(url)
except Exception as e:
print('body获取失败', e, url)
async def main():
tasks = []
sem = asyncio.Semaphore(100)
for i in range(1, 35):
url = 'https://www.17k.com/all/book/3_0_0__3__1__{}.html'.format(i)
task = asyncio.create_task(get_book_url(url, sem))
tasks.append(task)
await asyncio.wait(tasks)
print(len(all_book_url))
for i in all_book_url:
task = asyncio.create_task(get_page_urls(i, sem))
tasks.append(task)
await asyncio.wait(tasks)
print(len(all_book_list))
for book in all_book_list:
if not os.path.exists('./novel/{}'.format(book['title'])):
os.mkdir('./novel/{}'.format(book['title']))
print('处理 {}'.format(book['title']))
for i in range(len(book['urls'])):
task = asyncio.create_task(download_target(book['urls'][i], i, book['title'], sem))
tasks.append(task)
await asyncio.wait(tasks)
def merge_file(path):
top_file_list = os.listdir(path)
print(top_file_list)
try:
for book in top_file_list:
file_list = os.listdir(path + '/' + book)
file_list.sort()
for file in file_list:
with open('./book/{}.txt'.format(book), 'a+') as f:
with open('./novel/{}/'.format(book) + file, 'r') as file_f:
f.write(file_f.read())
shutil.rmtree(path + '/' + book)
except Exception as e:
print(e)
if __name__ == '__main__':
"""
version 1.0:
1. 获取章节URL
2. 从URL获取章节内容
3. 存储
version 1.5:
1. 获取所有免费小说的URL
2. 从URL获取章节内容
3. 存储
"""
start = int(time.time())
print(start)
asyncio.run(main())
merge_file('./novel')
end = int(time.time())
print(end)
print('抓取耗时:{}s'.format(end - start))
|