以前尝试过一些多线程的方式进行爬虫,现在体验一下协程的方式。
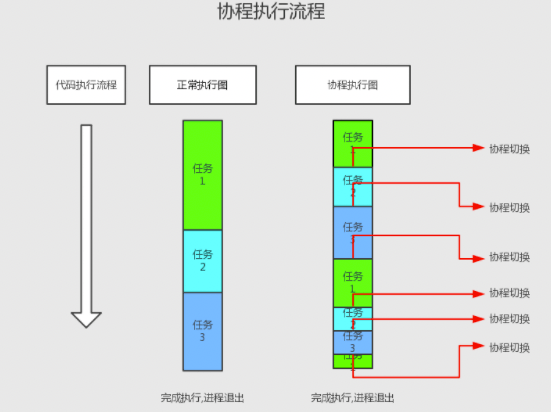
技术点 协程的概念 协程,Coroutine,又称微线程,是一种用户态的轻量级线程。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复之前保存的寄存器上下文和栈。因此协程能保留上一次调用时的状态,即局部状态的一个特定组合,每次过程重入时,就相当于进入上一次调用的状态。协程本质上是个单线程,相对于多进程来说,无需线程的上下文切换的开销,无需原子操作锁定及同步的开销。可以使用的场景,比如在网络爬虫的场景,发出一个请求之后,需要等待一定的实际才能得到响应。但是在等待过程中,程序可以做一些其他的事情,等到响应后再切回来继续处理,这样可以充分利用CPU和其他资源,也就是协程的优势所在。
协程的用法 协程相关的概念:
event_loop 事件循环,相当于一个无限循环,可以把一些函数注册到这个事件循环上,当满足条件时,就会调用对应的处理方法。 coroutine 协程,在 Python 中常指代为协程对象类型,可以将协程对象注册到事件循环中,会被事件循环调用。使用 async 关键字来定义一个方法,在调用时不会立即被执行,而是先放回一个协程对象。 task 任务,是对协程对象的进一步封装,包含了任务的所有状态。 详细讲解参考 关于协程的认知
xpath XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
选取节点 XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
表达式 描述 nodename 选取此节点的所有子节点。 / 从根节点选取(取子节点)。 // 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置(取子孙节点)。 . 选取当前节点. .. 选取当前节点的父节点。 @ 选取属性
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
路径表达式 结果 /bookstore/book[1] 选取属于 bookstore 子元素的第一个 book 元素。 /bookstore/book[last()] 选取属于 bookstore 子元素的最后一个 book 元素。 /bookstore/book[last()-1] 选取属于 bookstore 子元素的倒数第二个 book 元素。 /bookstore/book[position()<4] 选取最前面的3个属于 bookstore 元素的子元素的 book 元素。 //title[@lang] 选取所有拥有名为 lang 的属性的 title 元素。 //title[@lang=’eng’] 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 /bookstore/book[price>35.00] 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 /bookstore/book[price>35.00]//title选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00
逻辑 首先需要先分析一下要爬取的目标是什么?当然是所有的图片。
综上所述,流程如下:
获取专栏所有页面链接 获取每页上所有图片所属页面的链接 根据图片的链接进行下载和存储 获取专栏所有页面链接
本次示例目标是电脑壁纸专栏。
根据页面按钮获取第一页和最后一页的URL。其中第一页需要单独处理,之后的任意页都是递增的逻辑。而尾页直接提示767,直接使用即可,也可以复杂点使用xpath提取。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 page_urls = [] def get_page_urls1 (page_num ): if page_num == 1 : url = 'https://www.umei.cc/bizhitupian/diannaobizhi' else : url = 'https://www.umei.cc/bizhitupian/diannaobizhi/index_{}.htm' .format (page_num) resp = requests.get(url) html = etree.HTML(resp.text) table = html.xpath('//div[contains(@class,"item masonry_brick")]' ) if table: url_list = table[0 ].xpath('//div[contains(@class,"img")]/a/@href' ) page_urls.extend(url_list) def get_page_urls (): with ThreadPoolExecutor(100 ) as t: for i in range (1 , 6 ): args = [i] t.submit(lambda p: get_page_urls1(*p), args)
最终获取到了所有页面的链接。
获取每页上所有图片所属页面的链接
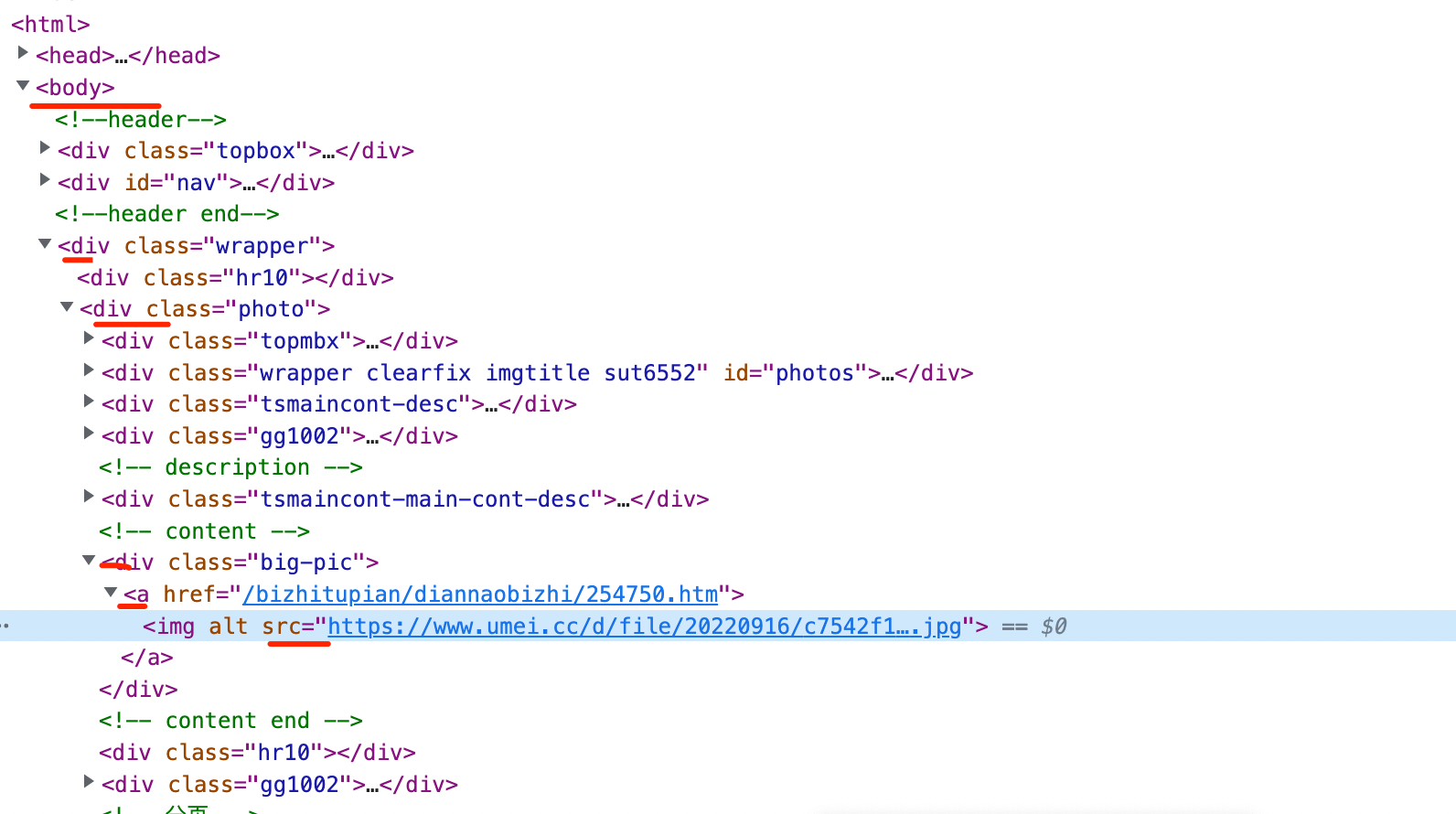
1 2 3 4 5 6 7 8 9 10 11 12 13 14 clean_urls = list () def get_pic_url1 (url ): url = 'https://www.umei.cc{}' .format (url) resp = requests.get(url) html = etree.HTML(resp.text) pic_link = html.xpath('//div[contains(@class,"big-pic")]/a/img/@src' )[0 ] clean_urls.append(pic_link) def get_pic_url (): with ThreadPoolExecutor(100 ) as t: for i in page_urls: args = [i] t.submit(lambda p: get_pic_url1(*p), args)
最终获取了所有图片的URL。
异步下载 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 async def main (): tasks = [] get_page_urls() get_pic_url() print ('即将下载的文件总数{}' .format (len (clean_urls))) sem = asyncio.Semaphore(15 ) for url in clean_urls: task = asyncio.create_task(download_pic(url, sem)) tasks.append(task) await asyncio.wait(tasks) async def download_pic (url, sem ): name = '../pic/' + url.rsplit('/' , 1 )[1 ] timeout = aiohttp.ClientTimeout(total=300 ) headers = { "User-Agent" : random_useragent(), "Content-Type" : "application/x-www-form-urlencoded; charset=UTF-8" , } conn = aiohttp.TCPConnector(limit=10 ) async with sem: async with aiohttp.ClientSession(connector=conn, timeout=timeout) as session: async with session.get(url, headers=headers) as resp: async with aiofiles.open (name, 'wb' ) as f: await f.write(await resp.content.read()) print ('下载完成{}' .format (name))
在处理这一步的时候遇到了一些问题,可能是并发太高,导致经常遇到链接断开或者超时的情况,因此使用了Semaphore来控制协程的并发。
整体代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 """ @time:2022/09/28 @file:aiohttp_umei.cc.py @author:medivh @IDE:PyCharm """ import asyncioimport aiohttpimport aiofilesimport requestsfrom lxml import etreeimport timefrom concurrent.futures import ThreadPoolExecutorfrom utils import random_useragentasync def download_pic (url, sem ): name = '../pic/' + url.rsplit('/' , 1 )[1 ] timeout = aiohttp.ClientTimeout(total=300 ) headers = { "User-Agent" : random_useragent(), "Content-Type" : "application/x-www-form-urlencoded; charset=UTF-8" , } conn = aiohttp.TCPConnector(limit=10 ) async with sem: async with aiohttp.ClientSession(connector=conn, timeout=timeout) as session: async with session.get(url, headers=headers) as resp: async with aiofiles.open (name, 'wb' ) as f: await f.write(await resp.content.read()) print ('下载完成{}' .format (name)) def get_page_url (): urls = [] for page_num in range (1 , 2 ): if page_num == 1 : url = 'https://www.umei.cc/bizhitupian/diannaobizhi' else : url = 'https://www.umei.cc/bizhitupian/diannaobizhi/index_{}.htm' .format (page_num) resp = requests.get(url) html = etree.HTML(resp.text) table = html.xpath('//div[contains(@class,"item masonry_brick")]' ) if table: url_list = table[0 ].xpath('//div[contains(@class,"img")]//@href' ) urls.extend(url_list) return urls page_urls = [] def get_page_urls1 (page_num ): if page_num == 1 : url = 'https://www.umei.cc/bizhitupian/diannaobizhi' else : url = 'https://www.umei.cc/bizhitupian/diannaobizhi/index_{}.htm' .format (page_num) resp = requests.get(url) html = etree.HTML(resp.text) table = html.xpath('//div[contains(@class,"item masonry_brick")]' ) if table: url_list = table[0 ].xpath('//div[contains(@class,"img")]/a/@href' ) page_urls.extend(url_list) def get_page_urls (): with ThreadPoolExecutor(100 ) as t: for i in range (1 , 6 ): args = [i] t.submit(lambda p: get_page_urls1(*p), args) clean_urls = list () def get_pic_url1 (url ): url = 'https://www.umei.cc{}' .format (url) resp = requests.get(url) html = etree.HTML(resp.text) pic_link = html.xpath('//div[contains(@class,"big-pic")]/a/img/@src' )[0 ] clean_urls.append(pic_link) def get_pic_url (): with ThreadPoolExecutor(100 ) as t: for i in page_urls: args = [i] t.submit(lambda p: get_pic_url1(*p), args) async def main (): tasks = [] get_page_urls() get_pic_url() print ('即将下载的文件总数{}' .format (len (clean_urls))) sem = asyncio.Semaphore(15 ) for url in clean_urls: task = asyncio.create_task(download_pic(url, sem)) tasks.append(task) await asyncio.wait(tasks) if __name__ == '__main__' : """ 1. 拼接URL 1-767 2. 从URL获取图片链接 3. 下载图片 """ start = int (time.time()) print (start) asyncio.run(main()) end = int (time.time()) print (end) print ('抓取耗时:{}s' .format (end - start))
user-agent 可以自定义
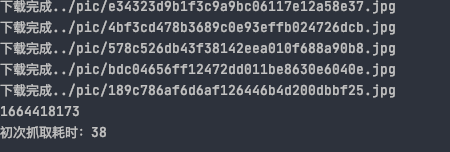
最终下载了5页图片,149张。
总结 参考: