安装 pip 1 2 3 pip install Alfred-Workflow pip install --target=. Alfred-Workflow
只支持Python2版本,Python3的话需要考虑兼容问题。
文件下载 有个1.40.0 版本的较为新一点 Alfred-Workflow-1.40.0.tar.gz
兼容问题 这个库是使用 Python2 写的,直接在 Python3 上使用会有问题,如果你习惯使用 Python3,可以有一些办法做一些兼容。
基础准备如下:
首先在使用 pip 安装时,要记得选择使用 Python2 安装 跟 Workflow 相关的操作放在一个文件里(称为 a.py),使用 Python2 作为解释器 把真正的逻辑放到另一个文件里(称为 b.py),使用 Python3 作为解释器 工作过程:
a.py 接收参数后,使用 subprocess 模块提供的功能,传递到 b.py 文件传输 b.py 可以通过文件读写、数据库或者标准输出的方式,把结果再传回 a.py 再读取 b.py 执行的结果,完成 Alfred 内条目的添加 目录结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Your Workflow/ info.plist icon.png workflow/ __init__.py background.py notify.py Notify.tgz update.py version web.py workflow.py yourscript.py etc.
开发 前提调研 起初用的是某位老哥开发的一个workflow,但是近两天发现有道的API下线了,事实上是HTTP版本的接口下线了,现在就只保留了一个新版本的API。
那就注册一个自己的开发者账号,填上认证信息,改改还能用。但是第二天一看,前天查俩单词就扣费了7分钱,虽说费用很低,但是架不住时间长了啊,何况认证用户只送50元的体验金,说不定哪天就用完了。
后来想了想还是自己开发一个新的,和有道翻译说再见了。在网上随便一搜看到了百度的通用翻译API,每个月权益如下,虽然不多但也够用了。
QPS=1 支持28个语种互译 单次最长请求1000字符 免费调用量5万字符/月 其实后来又看到很多其他家的产品,QPS都较高,免费额度也不错,比如腾讯云、阿里云等等。总之有一个能用就行了,就算将来再换也看文档改一下就行了。
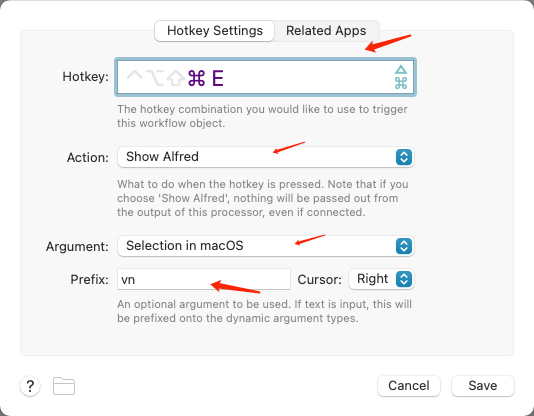
软件配置 首先点击加号新建,使用hotkey的方式
然后配置hotkey
注意箭头标识的部分不要写错,prefix的值也是唯一的,不然就冲突了。
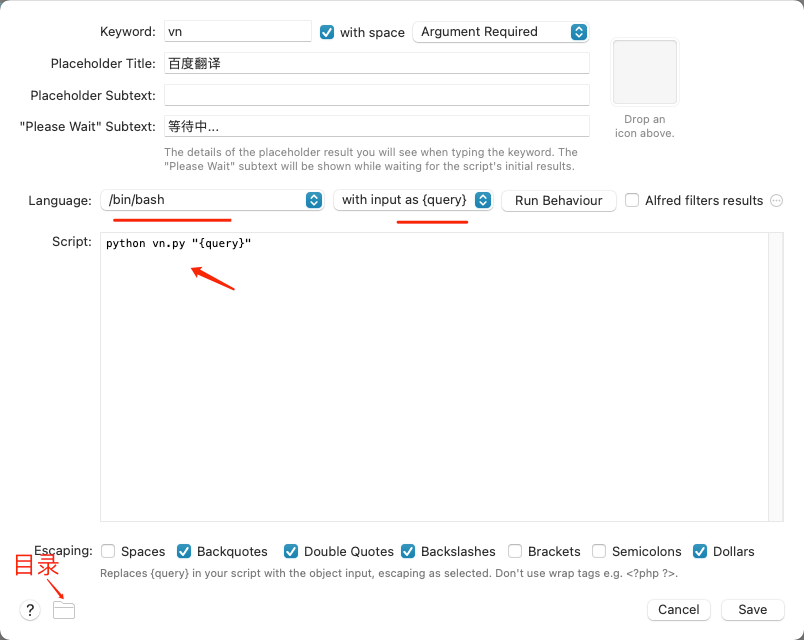
之后配置脚本部分
这里的语言选择了bash,但是脚本是单独存放的,点击下面的目录可以看到当前的workflow的存放位置,将开发脚本放在那个目录下,别忘了还有最开始下载的Alfred-Workflow。
代码 首先调试翻译的代码,从官网上下载稍微修改了一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import sysimport requestsimport randomfrom hashlib import md5appid = 'xxxxxxxxx' appkey = 'xxxxxxxx' endpoint = 'http://api.fanyi.baidu.com/api/trans/vip/translate' def translate_text (query ): salt = random.randint(32768 , 65536 ) sign = md5((appid + query + str (salt) + appkey).encode('utf-8' )).hexdigest() payload = {'appid' : appid, 'q' : query, 'from' : 'auto' , 'to' : 'auto' , 'salt' : salt, 'sign' : sign} try : r = requests.post(endpoint, params=payload) r.raise_for_status() res = r.json().get('trans_result' , [{'dst' : r.json()}])[0 ]['dst' ] return res except requests.exceptions.RequestException as e: return {'error' : 'Network error: {}' .format (e)} except ValueError as e: return {'error' : 'JSON parsing error: {}' .format (e)} if __name__ == "__main__" : query = ' ' .join(sys.argv[1 :]) result = translate_text(query) print (result)
主程序中获取子进程的输出结果,可以考虑以下两种方式:
使用 print(result) 输出,并通过 subprocess.check_output() 来获取子进程的输出结果。这种方式在示例代码中已经使用,并且是相对简单和直接的方式。 将子进程的输出写入到文件中,然后在主进程中读取文件来获取输出结果。这样可以绕过无法直接获取子进程输出的问题。 调试完成后会根据输入的语言翻译成对应的语言。之后再配置刚才截图中使用的vn.py:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import sysimport subprocessfrom workflow import Workflow3API_KEY = 'your-pinboard-api-key' def main (wf ): args = wf.args result = subprocess.check_output(['python3' , 'Baidu_Text_transAPI.py' ] + args, universal_newlines=True ).decode( 'utf-8' ) wf.logger.info(u"翻译结果:%s" , result) wf.add_item( title=args[0 ], subtitle=u"翻译结果: " + result, valid=True , uid="url here" , arg=result ) wf.send_feedback() if __name__ == u"__main__" : wf = Workflow3() sys.exit(wf.run(main))
调试过程中很痛苦,主要是必须顾虑到Python2的写法,在中文编码和ASCII上折腾了很久,还是Python3用着爽,可惜deanise大神没这打算。
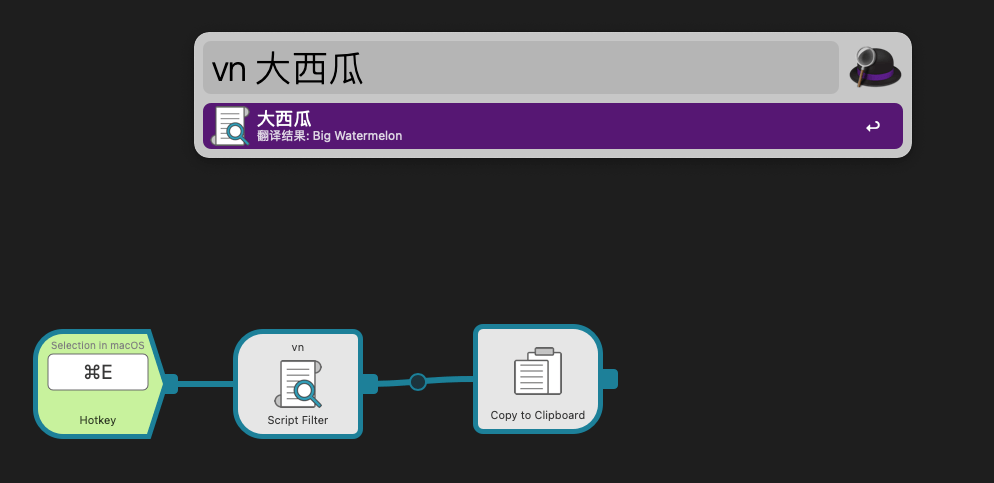
结果
调试的时候可以点开右上角的蜘蛛,会展示debug信息。
参考